Lock-free programming is a challenge, not just because of the complexity of the task itself, but because of how difficult it can be to penetrate the subject in the first place.
I was fortunate in that my first introduction to lock-free (also known as lockless) programming was Bruce Dawson’s excellent and comprehensive white paper, Lockless Programming Considerations. And like many, I’ve had the occasion to put Bruce’s advice into practice developing and debugging lock-free code on platforms such as the Xbox 360.
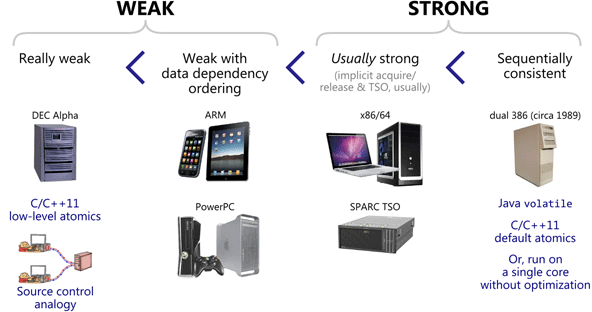
Since then, a lot of good material has been written, ranging from abstract theory and proofs of correctness to practical examples and hardware details. I’ll leave a list of references in the footnotes. At times, the information in one source may appear orthogonal to other sources: For instance, some material assumes sequential consistency, and thus sidesteps the memory ordering issues which typically plague lock-free C/C++ code. The new C++11 atomic library standard throws another wrench into the works, challenging the way many of us express lock-free algorithms.
In this post, I’d like to re-introduce lock-free programming, first by defining it, then by distilling most of the information down to a few key concepts. I’ll show how those concepts relate to one another using flowcharts, then we’ll dip our toes into the details a little bit. At a minimum, any programmer who dives into lock-free programming should already understand how to write correct multithreaded code using mutexes, and other high-level synchronization objects such as semaphores and events.
What Is It?
People often describe lock-free programming as programming without mutexes, which are also referred to as locks. That’s true, but it’s only part of the story. The generally accepted definition, based on academic literature, is a bit more broad. At its essence, lock-free is a property used to describe some code, without saying too much about how that code was actually written.
 Preshing on Programming
Preshing on Programming