 Preshing on Programming
Preshing on ProgrammingIn an earlier post, I showed how to implement the “world’s simplest lock-free hash table” in C++. It was so simple that you couldn’t even delete entries or resize the table. Well, a few years have passed since then, and I’ve recently written some concurrent maps without those limitations. You’ll find them in my Junction project on GitHub.
Junction contains several concurrent maps – even the ‘world’s simplest’ is there, under the name ConcurrentMap_Crude. For brevity, let’s call that one the Crude map. In this post, I’ll explain the difference between the Crude map and Junction’s Linear map. Linear is the simplest Junction map that supports both resize and delete.
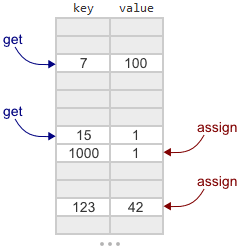
You can review the original post for an explanation of how the Crude map works. To recap: It’s based on open addressing and linear probing. That means it’s basically a big array of keys and values using a linear search. When inserting or looking up a given key, you hash the key to determine where to begin the search. Concurrent inserts and lookups are permitted.
Junction’s Linear map is based on the same principle, except that when the array gets too full, its entire contents are migrated to a new, larger array. When the migration completes, the old table is replaced with the old one. So, how do we achieve that while still allowing concurrent operations? The Linear map’s approach is based on Cliff Click’s non-blocking hash map in Java, but has a few differences.
The Data Structure
First, we need to modify our data structure a little bit. The original Crude map had two data members: A pointer m_cells and an integer m_sizeMask.
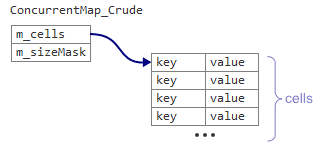
The Linear map instead has a single data member m_root, which points to a Table structure followed by the cells themselves in a single, contiguous memory block.
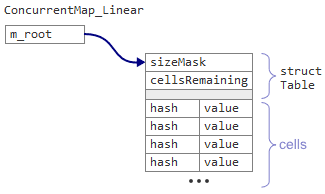
In the Table structure, there’s a new shared counter cellsRemaining, initially set to 75% of the table size. Whenever a thread tries to insert a new key, it decrements cellsRemaining first. If it decrements cellsRemaining below zero, that means the table is overpopulated, and it’s time to migrate everything to a new table.
With this new data structure, we can simultaneously replace the table, sizeMask and cellsRemaining all in a single atomic step, simply by reassigning the m_root pointer.
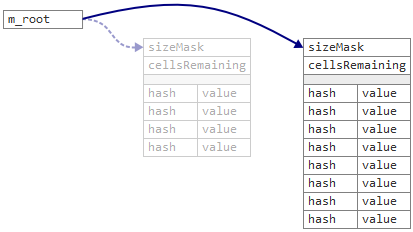
Another difference between the two maps is that the Linear map stores hashed keys instead of raw keys. That makes migrations faster, since we never need to recompute the hash function. Junction’s hash function is invertible, too, so it’s always possible to recover an original key from a hashed one.
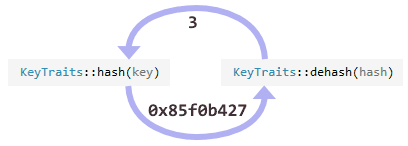
Because the hash function is invertible, finding an existing key is as simple as finding its hash. That’s why currently, Junction only supports integer and raw pointer keys. (In my opinion, the best way to support more complex keys would be to implement a concurrent set instead of a map.)
Migrating to a New Table – The Incorrect Way
Now that we know when a migration should begin, let’s turn to the challenge of actually performing that migration. Essentially, we must identify every cell that’s in use in the old table and insert a copy of it into the new table. Some entries will end up at the same array index, some will end up at a higher index, and others will shift closer to their ideal index.
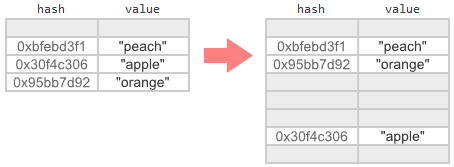
Of course, if other threads can still modify the old table during migration, things are not so simple. If we take a naïve approach, we risk losing changes. For example, suppose we have a map that’s almost full when two threads perform the following:
- Thread 1 calls
assign(2, "apple"), decrementingcellsRemainingto 0. - Thread 2 enters
assign(14, "peach")and decrementscellsRemainingto -1. A migration is needed. - Thread 2 migrates the contents of the old table to a new table, but doesn’t publish the new table yet.
- Thread 1 calls
assign(2, "banana")on the old table. Because a cell already exists for this key, the function doesn’t decrementcellsRemaining. It simply replaces “apple” with “banana” in the old cell. - Thread 2 publishes the new table to
m_root, wiping out Thread 1’s changes. - Thread 1 calls
get(2)on the new table.
At this point, we would like get(2) to return “banana”, because this key was only modified by a single thread, and that was the last value it wrote. Unfortunately, get(2) will return the older value “apple”, which is incorrect. We need a better migration strategy.
Migrating to a New Table Safely
To prevent that problem, we could block concurrent modifications using a read-write lock, although in this case, ‘shared-exclusive lock’ would be a better description. In that strategy, any function that modifies the contents of the table would take the shared lock first. The thread that migrates the table would take the exclusive lock. And thanks to QSBR, get wouldn’t need any lock at all.
The Linear map doesn’t do that. It goes a step further, so that even modifications don’t require a shared lock. Essentially, as the migration proceeds through the old table, it replaces each cell’s value field with a special Redirect marker.

All map operations are impacted by this change. In particular, the assign function can’t just blindly modify a cell’s value anymore. It must perform a read-modify-write on value instead, to avoid overwriting the Redirect marker if one has been placed. If it sees a Redirect marker in value, that means a new table exists, and the operation should be performed in the new table instead.
Now, if we allow concurrent operations while a migration is in progress, then clearly, we must maintain consistent values for each key between the two tables. Unfortunately, there’s no way to atomically write Redirect to an old cell while simultaneously copying its previous value to a new cell. Nonetheless, we can still ensure consistency by migrating each value using a loop. This is the loop Linear maps use:
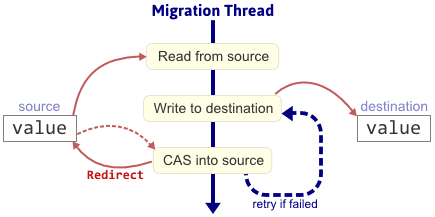
In this loop, it’s still possible for racing threads to modify the source value immediately after the migration thread reads it, since a Redirect marker hasn’t been placed there yet. In that case, when the migration thread tries to change the source to Redirect via CAS, the CAS will fail and the operation will retry using the updated value. As long as the source value keeps changing, the migration thread will keep retrying, but eventually it will succeed. This strategy allows concurrent get calls to safely find values in the new table, but concurrent assign calls cannot modify the new table until the migration is complete. (Cliff Click’s hash map doesn’t have that limitation, so his migration loop involves a few more steps.)
In the current version of Linear, even get calls don’t read from the new table until the migration is complete. Therefore, in the current version, a loop is not really necessary; the migration could be implemented as an atomic exchange of the source value followed by a plain store to the destination value. (I just realized that while writing this post.) Right now, if a get call encounters a Redirect, it helps complete the migration. Perhaps it would be better for scalability if it immediately read from the new table instead. That’s something worth investigating.
Multithreaded Migration
The Table structure has some additional data members I didn’t mention earlier. One member is jobCoordinator. During migration, the jobCoordinator points to a TableMigration object that represents the migration in progress. This is where the new table is stored before it gets published to m_root. I won’t go into details, but the jobCoordinator allows multiple threads to participate in the migration in parallel.
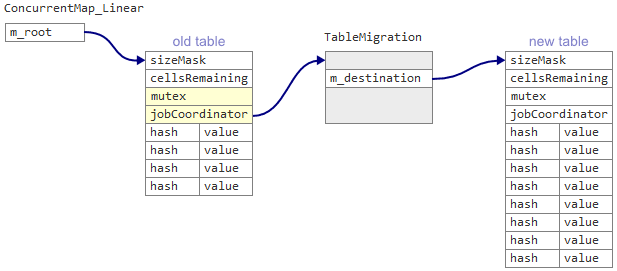
What if multiple threads try to begin a migration at the same time? In the event of such a race, Linear maps use double-checked locking to prevent duplicate TableMigration objects from being created. That’s why each Table has a mutex. (Cliff Click’s hash map differs here, too. He allows racing threads to create new tables optimistically.)
I haven’t said much about the Linear map’s erase function in this post. That’s because it’s easy: It simply changes the cell’s value to the special NullValue, the same value used to initialize a cell. The cell’s hash field, however, is left unchanged. That means the table may eventually fill up with deleted cells, but those cells will be purged when migrating to a new table. There are a few remaining details about choosing the size of the destination table, but I’ll skip those details here.
That’s the Linear map in a nutshell! Junction’s Leapfrog and Grampa maps are based on the same design, but extend it in different ways.
Concurrent programming is difficult, but I feel that a better understanding is worth pursuing, since multicore processors are not going away. That’s why I wanted to share the experience of building the Linear map. Examples are a powerful way to learn, or at least to become familiar with the problem domain.