 Preshing on Programming
Preshing on ProgrammingIf you want to support multiple readers for a data structure, while protecting against concurrent writes, a read-write lock might seem like the only way – but it isn’t! You can achieve the same thing without a read-write lock if you allow several copies of the data structure to exist in memory. You just need a way to delete old copies when they’re no longer in use.
Let’s look at one way to achieve that in C++. We’ll start with an example based on a read-write lock.
Using a Read-Write Lock
Suppose you have a network server with dozens of threads. Each thread broadcasts messages to dozens of connected clients. Once in a while, a new client connects or an existing client disconnects, so the list of connected clients must change. We can store the list of connected clients in a std::vector and protect it using a read-write lock such as std::shared_mutex.
class Server { private: std::shared_mutex m_rwLock; // Read-write lock std::vector<int> m_clients; // List of connected clients public: void broadcast(const void* msg, size_t len) { std::shared_lock<std::shared_mutex> shared(m_rwLock); // Shared lock for (int fd : m_clients) send(fd, msg, len, 0); } void addClient(int fd) { std::unique_lock<std::shared_mutex> exclusive(m_rwLock); // Exclusive lock m_clients.push_back(fd); } ...
The broadcast function reads from the list of connected clients, but doesn’t modify it, so it takes a read lock (also known as a shared lock). addClient, on the other hand, needs to modify the list, so it takes a write lock (also known as an exclusive lock).
That’s all fine and dandy. Now let’s eliminate the read-write lock by allowing multiple copies of the list to exist at the same time.
Eliminating the Read-Write Lock
First, we must establish an atomic pointer to the current list. This pointer will hold the most up-to-date list of connected clients at any moment in time.
class Server { private: struct ClientList { std::vector<int> clients; }; std::atomic<ClientList*> m_currentList; // The most up-to-date list public: ...
The broadcast function copies that pointer to a local variable, then uses that local variable for the remainder of the function. Note that the shared lock has been eliminated. That reduces the number of modifications to shared memory, which is better for scalability.
void broadcast(const void* msg, size_t len) { ClientList* list = m_currentList.load(); // Atomic load from m_currentList for (int fd : list->clients) send(fd, msg, len); }
The addClient function, called less frequently, makes a new, private copy of the list, modifies the copy, then publishes the new copy back to the atomic pointer. For simplicity, let’s assume all calls to addClient are made from a single thread. (If calls were made from multiple threads, we’d need to protect addClient with a mutex or a CAS loop.)
void addClient(int fd) { ClientList* oldList = m_currentList.load(); // Atomic load from m_currentList ClientList* newList = new ClientList{*oldList}; // Make a private copy newList->clients.push_back(fd); // Modify it m_currentList.store(newList); // Publish the new copy // *** Note: Must do something with the old list here *** }
At the moment when m_currentList is replaced, other threads might still be using the old list, but that’s fine. We allow it.

We aren’t done yet, though. addClient needs to do something with the old list. We can’t delete the old list immediately, since other threads might still be using it. And we can’t not delete it, since that would result in a memory leak. Let’s introduce a new object that’s responsible for deleting old lists at a safe point in time. We’ll call it a MemoryReclaimer.
class Server { ... MemoryReclaimer m_reclaimer; ... void addClient(int fd) { ClientList* oldList = m_currentList.load(); // Atomic load from m_currentList ClientList* newList = new ClientList{*oldList}; // Make a private copy newList->clients.push_back(fd); // Modify it m_currentList.store(newList); // Publish the new copy m_reclaimer.addCallback([=](){ delete oldList }); } ...
It’s interesting to note that if this was Java, we wouldn’t need to introduce such a MemoryReclaimer. We could just stop referencing the old list, and Java’s garbage collector would eventually delete it. But this is C++, so we must clean up those old lists explicitly.
We notify MemoryReclaimer about objects to delete by passing a callback to addCallback. MemoryReclaimer must invoke this callback sometime after all threads are finished reading from the old object. It must also ensure that none of those threads will ever access the old object again. Here’s one way to achieve both goals.
Quiescent State-Based Reclamation
The approach I’ll describe here is known as quiescent state-based reclamation, or QSBR for short. The idea is to identify a quiescent state in each thread. A quiescent state is a bit like the opposite of a critical section. It’s some point in the thread’s execution that lies outside all related critical sections performed by that thread. For example, our broadcast function still contains a critical section, even though it doesn’t explicitly lock anymore, because it’s critical not to delete the list before the function returns. Therefore, at a very minimum, the quiescent state should lie somewhere outside the broadcast function.
Wherever we choose to put the quiescent state, we must notify the MemoryReclaimer object about it. In our case, we’ll require threads to call onQuiescentState. At a minimum, before invoking a given callback, the MemoryReclaimer should wait until all participating threads have called onQuiescentState first. Once that condition is satisfied, it is guaranteed that if any preceding critical sections used the old object, those critical sections have ended.
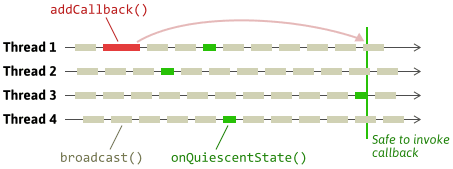
Finding a good place to call onQuiescentState for each thread is really application-specific. Ideally, in our example, it would be called much less often than the broadcast function – otherwise, we’d negate the benefit of eliminating the read-write lock in the first place. For example, it could be called after a fixed number of calls to broadcast, or a fixed amount of time, whichever comes first. If this was a game engine, it could be called on every iteration of the main loop, or some other coarse-grained unit of work.
Intervals
A simple implementation of MemoryReclaimer could work as follows. Instead of handling each callback individually, we can introduce the concept of intervals, and group callbacks together by interval. Once every thread has called onQuiescentState, the current interval is considered to end, and a new interval is considered to begin. At the end of each interval, we know that it’s safe to invoke all the callbacks added in the previous interval, because every participating thread has called onQuiescentState since the previous interval ended.
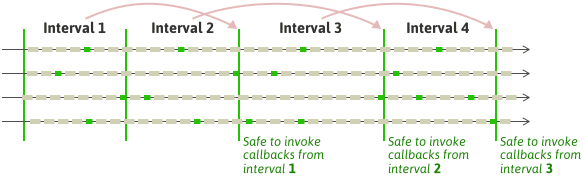
Here’s a quick implementation of such a MemoryReclaimer. It uses a bool vector to keep track of which threads have called onQuiescentState during the current interval, and which ones haven’t yet. Every participating thread in the system must call registerThread beforehand.
class MemoryReclaimer { private: std::mutex m_mutex; std::vector<bool> m_threadWasQuiescent; std::vector<std::function<void()>> m_currentIntervalCallbacks; std::vector<std::function<void()>> m_previousIntervalCallbacks; size_t m_numRemaining = 0; public: typedef size_t ThreadIndex; ThreadIndex registerThread() { std::lock_guard<std::mutex> guard(m_mutex); ThreadIndex id = m_threadWasQuiescent.size(); m_threadWasQuiescent.push_back(false); m_numRemaining++; return id; } void addCallback(const std::function<void()>& callback) { std::lock_guard<std::mutex> guard(m_mutex); m_currentIntervalCallbacks.push_back(callback); } void onQuiescentState(ThreadIndex id) { std::lock_guard<std::mutex> guard(m_mutex); if (!m_threadWasQuiescent[id]) { m_threadWasQuiescent[id] = true; m_numRemaining--; if (m_numRemaining == 0) { // End of interval. Invoke all callbacks from the previous interval. for (const auto& callback : m_previousIntervalCallbacks) { callback(); } // Move current callbacks to previous interval. m_previousIntervalCallbacks = std::move(m_currentIntervalCallbacks); m_currentIntervalCallbacks.clear(); // Reset all thread statuses. for (size_t i = 0; i < m_threadWasQuiescent.size(); i++) { m_threadWasQuiescent[i] = false; } m_numRemaining = m_threadWasQuiescent.size(); } } } };
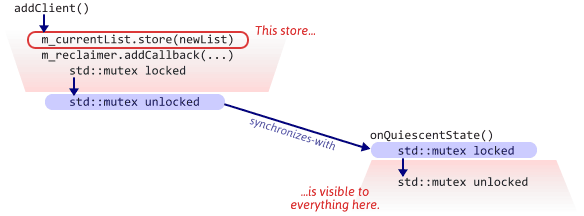
Not only does MemoryReclaimer guarantee that preceding critical sections have ended – when used correctly, it also ensures that no thread will ever use an old object again. Consider again our server’s addClient function. This function modifies m_currentList, which doesn’t necessarily become visible to other threads right away, then calls addCallback. addCallback locks a mutex, then unlocks it. According to the C++ standard (§30.4.1.2.11), the unlock will synchronize-with every subsequent lock of the same mutex, which in our case includes calls to onQuiescentState from other threads. As a result, the new value of m_currentList will automatically become visible to other threads when onQuiescentState is called.
That’s just one implementation of a MemoryReclaimer based on QSBR. It might be possible to implement a more efficient version, but I haven’t thought too hard about it. If you know of a better one, let me know in the comments.
Related Information
I’m not sure exactly when the term “QSBR” was coined, but it seems to have emerged from research into read-copy-update (RCU), a family of techniques that’s especially popular inside the Linux kernel. The memory reclamation strategy described in this post, on the other hand, takes place entirely at the application level. It’s similar to the QSBR flavor of userspace RCU.
I used this technique in Junction to implement a resizable concurrent map. Every time a map’s contents are migrated to a new table, QSBR is used to reclaim the memory of the old table. If Junction used read-write locks to protect those tables instead, I don’t think its maps would be as scalable.
QSBR is not the only memory reclamation strategy that exists. Tom Hart’s 2005 thesis gives a nice overview of other strategies. To be honest, I’ve never personally seen any of those techniques used in any C++ application or library besides Junction. If you have, I’d be interested to hear about it. I can only think of one or two instances where a game I worked on might have benefitted from QSBR, performance-wise.
QSBR can be used to clean up resources other than memory. For example, the server described in this post maintains a list of open file descriptors – one for each connected client. A safe strategy for closing those file descriptors could be based on QSBR as well.