 Preshing on Programming
Preshing on ProgrammingI wasn’t planning to write about lock-free programming again, but a commenter named Mike recently asked an interesting question on my Acquire and Release Semantics post from 2012. It’s a question I wondered about years ago, but could never really reconcile until (possibly) now.
A quick recap: A read-acquire operation cannot be reordered, either by the compiler or the CPU, with any read or write operation that follows it in program order. A write-release operation cannot be reordered with any read or write operation that precedes it in program order.
Those rules don’t prevent the reordering of a write-release followed by a read-acquire. For example, in C++, if A and B are std::atomic<int>, and we write:
A.store(1, std::memory_order_release); int b = B.load(std::memory_order_acquire);
…the compiler is free to reorder those statements, as if we had written:
int b = B.load(std::memory_order_acquire); A.store(1, std::memory_order_release);
And that’s fair. Why the heck not? On many architectures, including x86, the CPU could perform this reordering anyway.
Well, here’s where Mike’s question comes in. What if A and B are spinlocks? Let’s say that the spinlock is initially 0. To lock it, we repeatedly attempt a compare-and-swap, with acquire semantics, until it changes from 0 to 1. To unlock it, we simply set it back to 0, with release semantics.
Now, suppose Thread 1 does the following:
// Lock A int expected = 0; while (!A.compare_exchange_weak(expected, 1, std::memory_order_acquire)) { expected = 0; } // Unlock A A.store(0, std::memory_order_release); // Lock B while (!B.compare_exchange_weak(expected, 1, std::memory_order_acquire)) { expected = 0; } // Unlock B B.store(0, std::memory_order_release);
Meanwhile, Thread 2 does the following:
// Lock B int expected = 0; while (!B.compare_exchange_weak(expected, 1, std::memory_order_acquire)) { expected = 0; } // Lock A while (!A.compare_exchange_weak(expected, 1, std::memory_order_acquire)) { expected = 0; } // Unlock A A.store(0, std::memory_order_release); // Unlock B B.store(0, std::memory_order_release);
Check the highlighted lines in Thread 1. It’s a write-release followed by a read-acquire! I just said that acquire and release semantics don’t prevent the reordering of those operations. So, is the compiler free to reorder those statements? If it reorders those statements, then it would be as if we had written:
// Lock A int expected = 0; while (!A.compare_exchange_weak(expected, 1, std::memory_order_acquire)) { expected = 0; } // Lock B while (!B.compare_exchange_weak(expected, 1, std::memory_order_acquire)) { expected = 0; } // Unlock A A.store(0, std::memory_order_release); // Unlock B B.store(0, std::memory_order_release);
This version is quite different from the original code. In the original code, Thread 1 only held one spinlock at a time. In this version, Thread 1 obtains both spinlocks. This introduces a potential deadlock in our program: Thread 1 could successfully lock A, but get stuck waiting for lock B; and Thread 2 could successfully lock B, but get stuck waiting for lock A.
That’s bad.
However, I’m not so sure the compiler is allowed to reorder those statements. Not because of acquire and release semantics, but because of a different rule from the C++ standard. In working draft N4659, section 4.7.2:18 states:
An implementation should ensure that the last value (in modification order) assigned by an atomic or synchronization operation will become visible to all other threads in a finite period of time.
So, getting back to Thread 1’s original code:
// Unlock A A.store(0, std::memory_order_release); // Lock B while (!B.compare_exchange_weak(expected, 1, std::memory_order_acquire)) { expected = 0; }
Once execution reaches the while loop, the last value assigned to A is 0. The standard says that this value must become visible to all other threads in a finite period of time. But what if the while loop is infinite? The compiler has no way of ruling that out. And if the compiler can’t rule out that the while loop is infinite, then it shouldn’t reorder the first highlighted line to occur after the loop. If it moves that line after an infinite loop, then it is violating §4.7.2:18 of the C++ standard.
Therefore, I believe the compiler shouldn’t reorder those statements, and deadlock is not possible. [Note: This is not an iron-clad guarantee; see the update at the end of this post.]
As a sanity check, I pasted Thread 1’s code into Matt Godbolt’s Compiler Explorer. Judging from the assembly code, none of the three major C++ compilers reorder those statements when optimizations are enabled. This obviously doesn’t prove my claim, but it doesn’t disprove it either.
I’ve wondered about this question ever since watching Herb Sutter’s Atomic Weapons talk from 2012. At the 44:35 mark in the video, he alludes to an example exactly like this one – involving spinlocks – and warns that the reordering of release/acquire operations could introduce deadlock, exactly as described here. I thought it was an alarming point.
Now I don’t think there’s anything to worry about. At least not in this example. Am I right, or am I misinterpreting §4.7.2:18 of the standard? It would be nice if a compiler developer or other expert could weigh in.
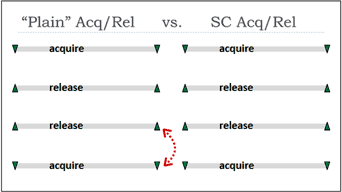
By the way, in that part of Herb’s talk, he describes the difference between what he calls “plain acquire and release” and “SC (sequentially consistent) acquire and release”. From what I can tell, the term “SC acquire and release” describes the behavior of the stlr and ldar instructions introduced in ARMv8. Those instructions were introduced to help implement C++’s sequentially consistent atomic operations more efficiently on ARM processors, as there is an implicit hardware #StoreLoad barrier between those instructions. However, neither a hardware #StoreLoad barrier nor C++’s sequentially consistent atomics are necessary to prevent the deadlock described in this post. All that’s needed is to forbid the compiler reordering I pointed out, which I believe the standard already does.
Finally, this post should not be taken as an endorsement of spin locks. I defer to Bruce Dawson’s advice on that subject. This post is just an attempt to better understand lock-free programming in C++.
Update (Jun 16, 2017)
Anthony Williams (author of C++ Concurrency in Action) states in the comments that he doesn’t think the above example can deadlock either.
Here’s a simpler example that illustrates the same question: thread2 busy-waits for a signal from thread1, then thread1 busy-waits for a signal from thread2. Is the compiler allowed to reorder the highlighted line to the end of thread1? If it does, neither thread will terminate.
std::atomic<int> A = 0; std::atomic<int> B = 0; void thread1() { A.store(1, std::memory_order_release); while (B.load(std::memory_order_acquire) == 0) { } } void thread2() { while (A.load(std::memory_order_acquire) == 0) { } B.store(1, std::memory_order_release); }
Nothing about acquire & release semantics seems to prohibit this particular reordering, but I still contend that the answer is no. Again, I’m assuming that the compiler follows N4659 §4.7.2:18, which says that once the abstract machine issues an atomic store, it should ultimately become visible to all other threads, though it may take a long time. If the above reordering did take place, it would be as if the abstract machine didn’t issue the store at all.
Part of the reason why this question is murky, at least for me, is that the standard’s wording is weak. §4.7.2:18 says that implementations “should” ensure that stores become visible, not that they must. It’s a recommendation, not a requirement.
Perhaps this weak wording was chosen because it’s possible to run C++ programs on a single CPU without any thread preemption (say, on an embedded system). In such an environment, all of the above examples are likely to livelock anyway – they can get stuck on the first loop. Stronger ordering constraints, such as memory_order_acq_rel or memory_order_seq_cst, won’t make the code any safer on such machines.
In the end, while memory_order_acquire and memory_order_release are certainly harder to synchronize than other ordering constraints, I don’t think they are more inherently deadlock-prone. Any evidence to the contrary is welcome.