 Preshing on Programming
Preshing on ProgrammingLock-free programming is a challenge, not just because of the complexity of the task itself, but because of how difficult it can be to penetrate the subject in the first place.
I was fortunate in that my first introduction to lock-free (also known as lockless) programming was Bruce Dawson’s excellent and comprehensive white paper, Lockless Programming Considerations. And like many, I’ve had the occasion to put Bruce’s advice into practice developing and debugging lock-free code on platforms such as the Xbox 360.
Since then, a lot of good material has been written, ranging from abstract theory and proofs of correctness to practical examples and hardware details. I’ll leave a list of references in the footnotes. At times, the information in one source may appear orthogonal to other sources: For instance, some material assumes sequential consistency, and thus sidesteps the memory ordering issues which typically plague lock-free C/C++ code. The new C++11 atomic library standard throws another wrench into the works, challenging the way many of us express lock-free algorithms.
In this post, I’d like to re-introduce lock-free programming, first by defining it, then by distilling most of the information down to a few key concepts. I’ll show how those concepts relate to one another using flowcharts, then we’ll dip our toes into the details a little bit. At a minimum, any programmer who dives into lock-free programming should already understand how to write correct multithreaded code using mutexes, and other high-level synchronization objects such as semaphores and events.
What Is It?
People often describe lock-free programming as programming without mutexes, which are also referred to as locks. That’s true, but it’s only part of the story. The generally accepted definition, based on academic literature, is a bit more broad. At its essence, lock-free is a property used to describe some code, without saying too much about how that code was actually written.
Basically, if some part of your program satisfies the following conditions, then that part can rightfully be considered lock-free. Conversely, if a given part of your code doesn’t satisfy these conditions, then that part is not lock-free.
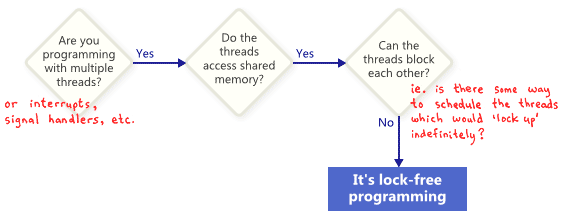
In this sense, the lock in lock-free does not refer directly to mutexes, but rather to the possibility of “locking up” the entire application in some way, whether it’s deadlock, livelock – or even due to hypothetical thread scheduling decisions made by your worst enemy. That last point sounds funny, but it’s key. Shared mutexes are ruled out trivially, because as soon as one thread obtains the mutex, your worst enemy could simply never schedule that thread again. Of course, real operating systems don’t work that way – we’re merely defining terms.
Here’s a simple example of an operation which contains no mutexes, but is still not lock-free. Initially, X = 0. As an exercise for the reader, consider how two threads could be scheduled in a way such that neither thread exits the loop.
while (X == 0) { X = 1 - X; }
Nobody expects a large application to be entirely lock-free. Typically, we identify a specific set of lock-free operations out of the whole codebase. For example, in a lock-free queue, there might be a handful of lock-free operations such as push, pop, perhaps isEmpty, and so on.
 Herlihy & Shavit, authors of The Art of Multiprocessor Programming
Herlihy & Shavit, authors of The Art of Multiprocessor Programming
One important consequence of lock-free programming is that if you suspend a single thread, it will never prevent other threads from making progress, as a group, through their own lock-free operations. This hints at the value of lock-free programming when writing interrupt handlers and real-time systems, where certain tasks must complete within a certain time limit, no matter what state the rest of the program is in.
A final precision: Operations that are designed to block do not disqualify the algorithm. For example, a queue’s pop operation may intentionally block when the queue is empty. The remaining codepaths can still be considered lock-free.
Lock-Free Programming Techniques
It turns out that when you attempt to satisfy the non-blocking condition of lock-free programming, a whole family of techniques fall out: atomic operations, memory barriers, avoiding the ABA problem, to name a few. This is where things quickly become diabolical.
So how do these techniques relate to one another? To illustrate, I’ve put together the following flowchart. I’ll elaborate on each one below.
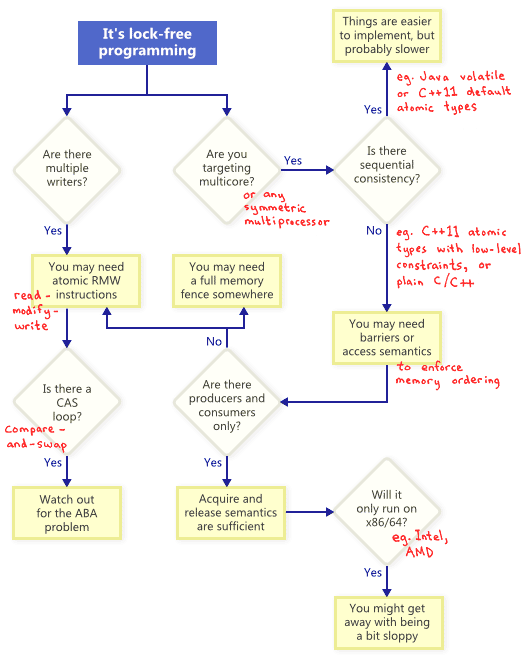
Atomic Read-Modify-Write Operations
Atomic operations are ones which manipulate memory in a way that appears indivisible: No thread can observe the operation half-complete. On modern processors, lots of operations are already atomic. For example, aligned reads and writes of simple types are usually atomic.
 Read-modify-write (RMW) operations go a step further, allowing you to perform more complex transactions atomically. They’re especially useful when a lock-free algorithm must support multiple writers, because when multiple threads attempt an RMW on the same address, they’ll effectively line up in a row and execute those operations one-at-a-time. I’ve already touched upon RMW operations in this blog, such as when implementing a lightweight mutex, a recursive mutex and a lightweight logging system.
Read-modify-write (RMW) operations go a step further, allowing you to perform more complex transactions atomically. They’re especially useful when a lock-free algorithm must support multiple writers, because when multiple threads attempt an RMW on the same address, they’ll effectively line up in a row and execute those operations one-at-a-time. I’ve already touched upon RMW operations in this blog, such as when implementing a lightweight mutex, a recursive mutex and a lightweight logging system.
Examples of RMW operations include _InterlockedIncrement on Win32, OSAtomicAdd32 on iOS, and std::atomic<int>::fetch_add in C++11. Be aware that the C++11 atomic standard does not guarantee that the implementation will be lock-free on every platform, so it’s best to know the capabilities of your platform and toolchain. You can call std::atomic<>::is_lock_free to make sure.
Different CPU families support RMW in different ways. Processors such as PowerPC and ARM expose load-link/store-conditional instructions, which effectively allow you to implement your own RMW primitive at a low level, though this is not often done. The common RMW operations are usually sufficient.
As illustrated by the flowchart, atomic RMWs are a necessary part of lock-free programming even on single-processor systems. Without atomicity, a thread could be interrupted halfway through the transaction, possibly leading to an inconsistent state.
Compare-And-Swap Loops
Perhaps the most often-discussed RMW operation is compare-and-swap (CAS). On Win32, CAS is provided via a family of intrinsics such as _InterlockedCompareExchange. Often, programmers perform compare-and-swap in a loop to repeatedly attempt a transaction. This pattern typically involves copying a shared variable to a local variable, performing some speculative work, and attempting to publish the changes using CAS:
void LockFreeQueue::push(Node* newHead) { for (;;) { // Copy a shared variable (m_Head) to a local. Node* oldHead = m_Head; // Do some speculative work, not yet visible to other threads. newHead->next = oldHead; // Next, attempt to publish our changes to the shared variable. // If the shared variable hasn't changed, the CAS succeeds and we return. // Otherwise, repeat. if (_InterlockedCompareExchange(&m_Head, newHead, oldHead) == oldHead) return; } }
Such loops still qualify as lock-free, because if the test fails for one thread, it means it must have succeeded for another – though some architectures offer a weaker variant of CAS where that’s not necessarily true. Whenever implementing a CAS loop, special care must be taken to avoid the ABA problem.
Sequential Consistency
Sequential consistency means that all threads agree on the order in which memory operations occurred, and that order is consistent with the order of operations in the program source code. Under sequential consistency, it’s impossible to experience memory reordering shenanigans like the one I demonstrated in a previous post.
A simple (but obviously impractical) way to achieve sequential consistency is to disable compiler optimizations and force all your threads to run on a single processor. A processor never sees its own memory effects out of order, even when threads are pre-empted and scheduled at arbitrary times.
Some programming languages offer sequentially consistency even for optimized code running in a multiprocessor environment. In C++11, you can declare all shared variables as C++11 atomic types with default memory ordering constraints. In Java, you can mark all shared variables as volatile. Here’s the example from my previous post, rewritten in C++11 style:
std::atomic<int> X(0), Y(0); int r1, r2; void thread1() { X.store(1); r1 = Y.load(); } void thread2() { Y.store(1); r2 = X.load(); }
Because the C++11 atomic types guarantee sequential consistency, the outcome r1 = r2 = 0 is impossible. To achieve this, the compiler outputs additional instructions behind the scenes – typically memory fences and/or RMW operations. Those additional instructions may make the implementation less efficient compared to one where the programmer has dealt with memory ordering directly.
Memory Ordering
As the flowchart suggests, any time you do lock-free programming for multicore (or any symmetric multiprocessor), and your environment does not guarantee sequential consistency, you must consider how to prevent memory reordering.
On today’s architectures, the tools to enforce correct memory ordering generally fall into three categories, which prevent both compiler reordering and processor reordering:
- A lightweight sync or fence instruction, which I’ll talk about in future posts;
- A full memory fence instruction, which I’ve demonstrated previously;
- Memory operations which provide acquire or release semantics.
Acquire semantics prevent memory reordering of operations which follow it in program order, and release semantics prevent memory reordering of operations preceding it. These semantics are particularly suitable in cases when there’s a producer/consumer relationship, where one thread publishes some information and the other reads it. I’ll also talk about this more in a future post.
Different Processors Have Different Memory Models
Different CPU families have different habits when it comes to memory reordering. The rules are documented by each CPU vendor and followed strictly by the hardware. For instance, PowerPC and ARM processors can change the order of memory stores relative to the instructions themselves, but normally, the x86/64 family of processors from Intel and AMD do not. We say the former processors have a more relaxed memory model.
There’s a temptation to abstract away such platform-specific details, especially with C++11 offering us a standard way to write portable lock-free code. But currently, I think most lock-free programmers have at least some appreciation of platform differences. If there’s one key difference to remember, it’s that at the x86/64 instruction level, every load from memory comes with acquire semantics, and every store to memory provides release semantics – at least for non-SSE instructions and non-write-combined memory. As a result, it’s been common in the past to write lock-free code which works on x86/64, but fails on other processors.
If you’re interested in the hardware details of how and why processors perform memory reordering, I’d recommend Appendix C of Is Parallel Programming Hard. In any case, keep in mind that memory reordering can also occur due to compiler reordering of instructions.
In this post, I haven’t said much about the practical side of lock-free programming, such as: When do we do it? How much do we really need? I also haven’t mentioned the importance of validating your lock-free algorithms. Nonetheless, I hope for some readers, this introduction has provided a basic familiarity with lock-free concepts, so you can proceed into the additional reading without feeling too bewildered. As usual, if you spot any inaccuracies, let me know in the comments.
[This article was featured in Issue #29 of Hacker Monthly.]
Additional References
 Anthony Williams’ blog and his book, C++ Concurrency in Action
Anthony Williams’ blog and his book, C++ Concurrency in Action- Dmitriy V’jukov’s website and various forum discussions
- Bartosz Milewski’s blog
- Charles Bloom’s Low-Level Threading series on his blog
- Doug Lea’s JSR-133 Cookbook
- Howells and McKenney’s memory-barriers.txt document
- Hans Boehm’s collection of links about the C++11 memory model
- Herb Sutter’s Effective Concurrency series
