 Preshing on Programming
Preshing on ProgrammingWhen debugging multithreaded code, it’s not always easy to determine which codepath was taken. You can’t always reproduce the bug while stepping through the debugger, nor can you always sprinkle printfs throughout the code, as you might in a single-threaded program. There might be millions of events before the bug occurs, and printf can easily slow the application to a crawl, mask the bug, or create a spam fest in the output log.
One way of attacking such problems is to instrument the code so that events are logged to a circular buffer in memory. This is similar to adding printfs, except that only the most recent events are kept in the log, and the performance overhead can be made very low using lock-free techniques.
Here’s one possible implementation. I’ve written it specifically for Windows in 32-bit C++, but you could easily adapt the idea to other platforms. The header file contains the following:
#include <windows.h> #include <intrin.h> namespace Logger { struct Event { DWORD tid; // Thread ID const char* msg; // Message string DWORD param; // A parameter which can mean anything you want }; static const int BUFFER_SIZE = 65536; // Must be a power of 2 extern Event g_events[BUFFER_SIZE]; extern LONG g_pos; inline void Log(const char* msg, DWORD param) { // Get next event index LONG index = _InterlockedIncrement(&g_pos); // Write an event at this index Event* e = g_events + (index & (BUFFER_SIZE - 1)); // Wrap to buffer size e->tid = ((DWORD*) __readfsdword(24))[9]; // Get thread ID e->msg = msg; e->param = param; } } #define LOG(m, p) Logger::Log(m, p)

 One limitation of the implementation I showed was that it was non-recursive. This means that if the same thread attempts to obtain the same lock twice, it will deadlock. In this post, I’ll show how to extend the implementation to support recursive locking.
One limitation of the implementation I showed was that it was non-recursive. This means that if the same thread attempts to obtain the same lock twice, it will deadlock. In this post, I’ll show how to extend the implementation to support recursive locking.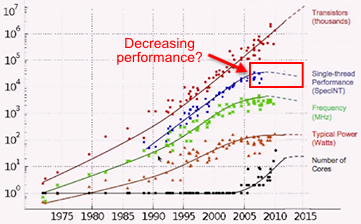
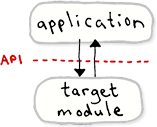 This particular profiling module is meant to act on one or more target modules in the application. A target module can be anything which exposes a well-defined
This particular profiling module is meant to act on one or more target modules in the application. A target module can be anything which exposes a well-defined  The Windows SDK provides two lock implementations for C/C++: the
The Windows SDK provides two lock implementations for C/C++: the  Other times, the conclusion that locks are slow is supported by a benchmark. For example,
Other times, the conclusion that locks are slow is supported by a benchmark. For example,