 Preshing on Programming
Preshing on ProgrammingPlywood is an open-source C++ framework I released a few weeks ago. It includes, among other things, a runtime module that exposes a cross-platform API for I/O, memory, threads, process management and more.
This post is about the I/O part. For those who don’t know, I/O stands for input/output, and refers to the part of a computer system that either writes serialized data to or reads serialized data from an external interface. The external interface could be a storage device, pipe, network connection or any other type of communication channel.

Typically, it’s the operating system’s responsibility to provide low-level I/O services to an application. But there’s still plenty of work that needs to happen at the application level, such as buffering, data conversion, performance tuning and exposing an interface that makes life easier on application programmers. That’s where Plywood’s I/O system comes in.
Of course, standard C++ already comes with its own input/output library, as does the standard C runtime, and most C and C++ programmers are quite familiar with those libraries. Plywood’s I/O system is meant serve as an alternative to those libraries. Those libraries were originally developed in 1984 and the early 1970s, respectively. They’ve stood the test of time incredibly well, but I don’t think it’s outrageous to suggest that, hey, maybe some innovation is possible here.
To be clear, when you build a project using Plywood, you aren’t required to use Plywood’s I/O system – you can still use the standard C or C++ runtime library, if you prefer.
I’m sure this blog post will seem dry for some (or many) readers – but not for me! I like this topic, and I’m willing bet that there are other low-level I/O wonks out there who will find it interesting as well. So let’s jump in.
Writing Raw Bytes to Standard Output
The following program writes "Hello!\n" to standard output as a raw sequence of 7 bytes. No newline conversion or character encoding conversion is performed. Writing takes place through an OutStream, which is a class (defined in the ply namespace) that performs buffered output.
#include <ply-runtime/Base.h> int main() { using namespace ply; OutStream outs = StdOut::binary(); outs.write({"Hello!\n", 7}); return 0; }
Now, suppose we pause this program immediately after the OutStream is created, before anything gets written. On a Linux system, this is what the OutStream initially looks like in memory:
-
This is the
OutStreamobject itself. As already mentioned,OutStreamis a class that performs buffered output. That means when you write to anOutStream, your data actually gets written to a temporary buffer in memory first. -
This is the temporary buffer used by the
OutStream.OutStream::curByteinitially points to the start of this buffer, andOutStream::endBytepoints to the end. The temporary buffer is 4096 bytes long, as indicated byChunkListNode::numBytes. -
This is a
ChunkListNode, a reference-counted object that owns the temporary buffer. It’s responsible for freeing the temporary buffer in its destructor. TheOutStreamholds a reference to this object. (The ability to create additionalChunkListNodereferences gives rise to some interesting features, but I’ll skip the details in this post.) -
This is an
OutPipe_FD, which is a subclass ofOutPipethat writes to a file descriptor. In this example, the file descriptor is1, which corresponds to standard output. TheOutStreamholds a pointer to this object, butOutStream::status.isPipeOwneris0, which means that theOutPipe_FDwon’t be destroyed when theOutStreamis destructed. That’s important, because this particularOutPipe_FDcan be shared by severalOutStreams.
From here, the program proceeds in two steps: First, the statement outs.write({"Hello!\n", 7}); is executed. This statement basically just copies the string "Hello!\n" to the temporary buffer and advances OutStream::curByte forward by 7 bytes. After that, we return from main, which invokes the OutStream destructor. The OutStream destructor flushes the contents of the temporary buffer to the OutPipe. That’s when the raw byte sequence for "Hello!\n" actually gets written to standard output.
There are other times when OutStream flushes its temporary buffer to the underlying OutPipe, too. For example, if we write several megabytes of data to the OutStream, the temporary buffer will get flushed each time it becomes full, which in this case happens every 4096 bytes. It’s also possible to flush the OutStream explicitly at any time by calling OutStream::flush().
I’m sure many readers will recognize the similarity between OutStream and std::ostream in C++ or FILE in C. It’s a high-level wrapper around a low-level output destination such as a file descriptor, and it performs buffering.
One difference between OutStream and those other stream types – and this might sound like a disadvantage at first – is that OutStream objects aren’t thread-safe. You must either manipulate each OutStream object from a single thread, or enforce mutual exclusion between threads yourself. That’s why there’s no single, global OutStream object that writes to standard output, like std::cout in C++ or stdout in C. Instead, if you need to write to standard output, you must call StdOut::binary() – or perhaps StdOut::text(), as we’ll see in the next example – to create a unique OutStream object.
Writing to Standard Output With Newline Conversion
In this next example, instead of creating an OutStream object, we create a StringWriter object that writes to standard output. StringWriter is a subclass of OutStream with additional member functions for writing text.
StringWriter does not extend OutStream with additional data members, so the two classes are actually interchangeable. Any time you have an OutStream object, you can freely cast it to StringWriter by calling OutStream::strWriter(). The main reason why OutStream and StringWriter are separate classes is to help express intention in the code. OutStreams are mainly intended to write binary data, and StringWriters are mainly intended to write text encoded in an 8-bit format compatible with ASCII, such as UTF-8.
#include <ply-runtime/Base.h> int main() { using namespace ply; StringWriter sw = StdOut::text(); sw << "Hello!\n"; return 0; }
In addition, StdOut::text installs an adapter that performs newline conversion. This is what it looks like in memory immediately after the StringWriter is created, before anything gets written:
The bottom half of the above diagram is identical to the previous diagram, and the top half of the diagram is basically an adapter. It’s a StringWriter (which derives from OutStream), with its own temporary buffer, pointing to a OutPipe_NewLineFilter. This time, status.isPipeOwner is 1, which means that the OutPipe_NewLineFilter will be automatically destroyed when the StringWriter is destructed.
When the StringWriter flushes the contents of its temporary buffer to the OutPipe_NewLineFilter, the OutPipe_NewLineFilter performs newline conversion on that data and writes the result to its own OutStream. Assuming this example runs on Linux, that basically just means discarding any \r (carriage return) character it encounters. If we run the same program on Windows, it will also replace any \n (linefeed) character it encounters with \r\n.
Personally, I think it’s a strange/funny convention that Windows applications tend to use \r\n to terminate lines of text, and applications on Unix-like platforms tend to use \n. There are historical reasons for this difference, but I don’t think there’s a very convincing reason for it anymore. Nonetheless, I’ve designed Plywood to play along, at least when StdOut::text() is called. You can always override the default behavior by calling StdOut::binary() and installing your preferred type of newline filter on it.
Finally, note that Plywood does not have the equivalent of std::endl. Instead, StringWriter generally expects \n to terminate lines of text, and lines aren’t flushed automatically. If you need to flush a StringWriter after writing a line of text, do so explicitly by calling OutStream::flush().
Writing UTF-16
In the previous example, there were two OutStreams chained together with an OutPipe_NewLineFilter acting as an adapter. Plywood has adapters that perform other conversions, too. For example, here’s a short program that saves a text file as UTF-16. The text file is written in little-endian byte order with Windows-style CRLF line endings, and includes a byte order mark (BOM) at the beginning of the file:
#include <ply-runtime/Base.h>
int main() {
using namespace ply;
TextFormat tf;
tf.encoding = TextFormat::Encoding::UTF16_le;
tf.newLine = TextFormat::NewLine::CRLF;
tf.bom = true;
Owned<StringWriter> sw = FileSystem::native()->openTextForWrite("utf16.txt", tf);
if (sw) {
*sw << "Hello!\n";
*sw << u8"😋🍺🍕\n";
}
return 0;
}
Here’s what the output file looks like when we open it in Visual Studio Code. You can see the expected information about the file format in the status bar: UTF-16 LE and CRLF.
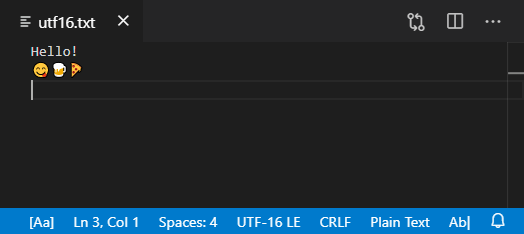
However, because Plywood generally prefers to work with UTF-8, the StringWriter returned from FileSystem::openTextForWrite() actually expects UTF-8-encoded text as input. That’s why the first line we passed to the StringWriter was the 8-bit character string "Hello!\n", and the second line was the string literal u8"😋🍺🍕\n", which uses the u8 string literal prefix. Both strings are valid UTF-8 strings at runtime. (In general, any time you use characters outside the ASCII character set, and you want UTF-8-encoded text at runtime, it’s a good idea to use the u8 prefix.)
As you might expect, the UTF-8 text passed to the StringWriter gets converted to UTF-16 using another adapter:
In general, it’s possible to create any kind of adapter that takes an input stream and writes an output stream. You could even implement an adapter that performs compression using zlib, encryption using OpenSSL, or any other compression/encryption codec. I’m sure Plywood will provide a few such adapters some point, but I haven’t had to implement them yet.
Reading Lines of Text
So far, all of the examples have involved writing output using either OutStream or StringWriter. This next one involves reading input using StringReader. StringReader is a subclass of InStream with additional member functions for reading and parsing text, and InStream is a class that performs buffered input from an underlying data source.
The following function opens a text file and read its contents to an array of Strings, with one array item per line:
Array<String> readLines() {
Array<String> result;
Owned<StringReader> sr = FileSystem::native()->openTextForReadAutodetect("utf16.txt").first;
if (sr) {
while (String line = sr->readString<fmt::Line>()) {
result.append(std::move(line));
}
}
return result;
}
The FileSystem::openTextForReadAutodetect() function attempts to guess the file format of the text file automatically. It looks for a byte order mark (BOM) and, if the BOM is missing, uses some heuristics to guess between UTF-8 and UTF-16. Again, because Plywood encourages working with UTF-8 text, the lines returned by the StringReader are always encoded in UTF-8 and terminated with \n, regardless of the source file’s original encoding and line endings. All necessary conversions are accomplished using adapters. For example, if we open the UTF-16 file that was written in the previous example, the chain of InStream objects would look like this:
This example works fine, but it will potentially perform a lot of memory allocations since every String object owns its own block of memory. An alternative way to extract lines of text from a file is to read the entire file into a String first – perhaps using FileSystem::loadTextAutodetect() – and create an array of StringView objects instead, using a function similar to the following:
Array<StringView> extractLines(StringView src) {
Array<StringView> result;
StringViewReader svr{src};
while (StringView line = svr.readView<fmt::Line>()) {
result.append(line);
}
return result;
}
This is the general approach used in Plywood’s built-in JSON, Markdown and C++ parsers. Source files are always loaded into memory first, then parsed in-place, avoiding additional memory allocations and string copies as much as possible. When using an approach like this, care must be taken to ensure that the original String remains valid as long as there are StringViews into it.
Writing to Memory
A StringWriter or OutStream doesn’t always have to write to an OutPipe. You can create a StringWriter that writes to memory simply by invoking its default constructor. After writing to such a StringWriter, you can extract its contents to a String by calling StringWriter::moveToString():
String getMessage() {
StringWriter sw;
sw << u8"OCEAN MAN 🌊 😍 ";
sw.format("Take me by the {} lead me to {} that you {}", u8"hand ✋", "land",
u8"understand 🙌 🌊");
return sw.moveToString();
}
Here’s what the StringWriter initially looks like in memory, before anything gets written. OutStream::status.type is 2, and instead of an OutPipe pointer, there’s a second Reference<ChunkListNode> member named headChunk. If we write a large amount of data to this StringWriter, we’ll end up with a linked list of ChunkListNodes in memory, with headChunk always pointing to the start of the linked list.
There’s a particular optimization that’s worth mentioning here. When working with a StringWriter like this one, each ChunkListNode object is located contiguously in memory after the memory buffer it owns. Therefore, when there’s just a single node in the linked list, and moveToString() is called, the existing memory buffer is truncated using realloc and returned directly. In other words, when creating a short String this way (smaller than 4 KB), only a single block of memory is allocated, written to and returned; no additional memory allocations or string copies are performed.
The previous example demonstrates using StringWriter::format() to write formatted text to an output stream. Plywood also provides a convenient wrapper function String::format() that hides the temporary StringWriter:
return String::format("The answer is {}.\n", 42);
If you wish to write to memory using an OutStream instead of a StringWriter, use the derived class MemOutStream. MemOutStream is mainly intended for writing binary data, but as mentioned earlier, there’s really nothing stopping you from casting it to a StringWriter using OutStream::strWriter() after it’s created.
Future Improvements
I hope you enjoyed this brief, meandering tour through Plywood’s I/O system. Here’s a quick list of potential future improvements to the system:
-
Plywood doesn’t have a bidirectional stream yet, like
std::iostreamin standard C++. As of this writing, onlyInStreamandOutStreamare implemented. -
Currently, the contents of
OutStream’s temporary buffer are always flushed using a synchronous function call. When writing to a file descriptor, better throughput could be achieved using the operating system’s asynchronous I/O support instead. When writing to an adapter, such as anOutPipe_TextConverteror a compression codec, better throughput could be achieved by processing the data in a background thread or using a job system. The main challenge will be to manage the lifetimes of multipleChunkListNodeobjects while I/O is pending. -
Plywood’s text conversion is only aware of UTF-8 and UTF-16 at this time. Some work was done towards ISO 8859-1 and Windows-1252, but support is not yet complete. Additional work is needed to support other encodings like Shift-JIS or GB 2312. The intention would still be to work with UTF-8 when text is loaded in memory, and convert between formats when performing I/O.