 Preshing on Programming
Preshing on ProgrammingIn an earlier post, I pointed out the importance of using a lightweight mutex. I also mentioned it was possible to write your own, provided you can live with certain limitations.
Why would you do such a thing? Well, in the past, some platforms (like BeOS) didn’t provide a lightweight mutex in the native API. Today, that’s not really a concern. I’m mainly showing this because it’s an interesting look at implementing synchronization primitives in general. As a curiosity, it just so happens this implementation shaves almost 50% off the overhead of the Windows Critical Section in the uncontended case. [Update: A closer look shows that under very high contention, a Windows Critical Section still performs much better.]
For the record, there are numerous ways to write your own mutex – or lock – entirely in user space, each with its own tradeoffs:
- Spin locks. These employ a busy-wait strategy which has the potential to waste CPU time, and in the worst case, can lead to livelock when competing threads run on the same core. Still, some programmers have found measurable speed improvements switching to spin locks in certain cases.
- Peterson’s algorithm is like a spinlock for two threads. A neat trick, but seems useless on today’s platforms. I find it noteworthy because Bartosz Milewski used this algorithm as a case study while discussing the finer points of the x86 memory model. Others have discussed Peterson’s lock in similar contexts.
- Charles Bloom has a long writeup describing various mutex implementations. Excellent information, but possibly greek to anyone unfamiliar with C++11’s atomics library and Relacy’s ($) notation.
Some of those implementations are pretty advanced. Here’s a relatively simple technique, using a semaphore and some atomic operations. I came up with it while writing my post about lock contention, but soon afterwards learned it was already in use as far back as 1996, when some engineers referred to it as the Benaphore. Here’s a C++ implementation for Win32, assuming an x86 CPU architecture:
#include <windows.h> #include <intrin.h> class Benaphore { private: LONG m_counter; HANDLE m_semaphore; public: Benaphore() { m_counter = 0; m_semaphore = CreateSemaphore(NULL, 0, 1, NULL); } ~Benaphore() { CloseHandle(m_semaphore); } void Lock() { if (_InterlockedIncrement(&m_counter) > 1) // x86/64 guarantees acquire semantics { WaitForSingleObject(m_semaphore, INFINITE); } } void Unlock() { if (_InterlockedDecrement(&m_counter) > 0) // x86/64 guarantees release semantics { ReleaseSemaphore(m_semaphore, 1, NULL); } } };
This implementation also serves as a convenient introduction to atomics, which are at the heart of many lock-free algorithms.
_InterlockedIncrement is an atomic read-modify-write (RMW) operation on Win32. If multiple threads attempt an atomic RMW at the same time, on the same piece of data, they will all line up in a row and execute one-at-a-time. This makes it possible to reason about what happens, and ensure correctness. It even works on multicore and multiprocessor systems.
Every modern processor provides some atomic RMW instructions, though the APIs provided by the toolchain may expose different meanings for the return values. On Win32, _InterlockedIncrement adds 1 to the specified integer and returns the new value. Since m_counter is initialized to 0, the first thread to call Lock will receive a return value of 1 from _InterlockedIncrement. As such, it skips over the WaitForSingleObject call and returns immediately. The lock now belongs to this thread, and life is peachy.
If another thread calls Lock while the first thread is still holding it, it will receive a return value of 2 from _InterlockedIncrement. This is a clue that the lock is already busy. At this point, it’s not safe to continue, so we bite the bullet and jump into one of those expensive kernel calls: WaitForSingleObject. This performs a decrement on the semaphore. We specified an initial count of 0 in CreateSemaphore, so the thread is now forced to wait until someone else comes along and increments this semaphore before it can proceed.
Next, suppose the first thread calls Unlock. The return value of _InterlockedDecrement will be 1. This is a clue that another thread is waiting for the lock, and that we should increment the semaphore using ReleaseSemaphore. The second thread is then able to continue, and it effectively obtains ownership of the lock.
Even if the timing is very tight, and the first thread calls ReleaseSemaphore before the second calls WaitForSingleObject, everything will function normally. And if you add a third, fourth or any number of other threads into the picture, that’s fine too. For good measure, you can even add a TryLock function to the implementation:
bool TryLock() { LONG result = _InterlockedCompareExchange(&m_counter, 1, 0); return (result == 0); }
Performance and Caveats
You might have noticed the underscore in front of _InterlockedIncrement. This is the compiler intrinsic version of InterlockedIncrement. It outputs a lock xadd instruction in place. And since Lock is defined right inside the class definition of Benaphore, the compiler treats it as an inline function. A call to Benaphore::Lock compiles down to 10 instructions using default Release settings, and there are no function calls in the uncontended case. Here’s the disassembly:
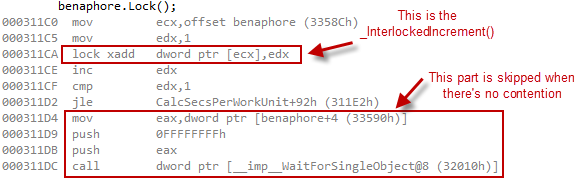
In the uncontended case, the Benaphore even outperforms a Critical Section on Win32. I timed a pair of uncontended lock/unlock operations, just as I previously did for the Mutex and Critical Section, and found the following timings:

If you have an application which is hitting a lock millions of times per second on Win32, this Benaphore implementation just might boost your overall performance by a couple of percent. [Update: I tried it. It doesn’t.] If you forego the intrinsics and just use regular, non-intrinsic version of the atomics, an indirect call into kernel32.dll is involved, so the Benaphore loses some of its edge: 49.8 ns on my Core 2 Duo.
Furthermore, with some (fairly heavy) code modifications, you could even share this Benaphore between processes – something Critical Section isn’t capable of. You’d have to put m_counter in shared memory, and use a named semaphore. However, depending on your use case, this might defeat the purpose of having separate processes in the first place. If one process terminates at the wrong moment, it could leave the Benaphore in an inconsistent state, and take the other processes down with it.
This implementation is non-recursive. If the same thread attempts to lock the same Benaphore twice, it will deadlock. In my next post, I’ll extend the implementation to allow recursion.
If you port this code to another CPU architecture, such as that in the Xbox 360 or a multicore iOS device, you’ll have to replace the _InterlockedIncrement macro with something which explicitly guarantees acquire and release semantics.
Finally, if you do use the Benaphore on another platform, be aware that it may introduce the possibility of priority inversion. For example, MacOS X and Linux avoid priority inversion by performing priority inheritance when you take a POSIX lock. If you use a Benaphore, you’ll bypass this OS mechanism, and it won’t be able to help you. Things are different on Windows, though: Windows fights priority inversion by randomly boosting the priority of starving threads, which behaves the same regardless of your choice of synchronization primitive.