 Preshing on Programming
Preshing on Programming In an earlier post, I explained how atomic operations let you manipulate shared variables concurrently without any torn reads or torn writes. Quite often, though, a thread only modifies a shared variable when there are no concurrent readers or writers. In such cases, atomic operations are unnecessary. We just need a way to safely propagate modifications from one thread to another once they’re complete. That’s where the synchronizes-with relation comes in.
In an earlier post, I explained how atomic operations let you manipulate shared variables concurrently without any torn reads or torn writes. Quite often, though, a thread only modifies a shared variable when there are no concurrent readers or writers. In such cases, atomic operations are unnecessary. We just need a way to safely propagate modifications from one thread to another once they’re complete. That’s where the synchronizes-with relation comes in.
”Synchronizes-with” is a term invented by language designers to describe ways in which the memory effects of source-level operations – even non-atomic operations – are guaranteed to become visible to other threads. This is a desirable guarantee when writing lock-free code, since you can use it to avoid unwelcome surprises caused by memory reordering.
”Synchronizes-with” is a fairly modern computer science term. You’ll find it in the specifications of C++11, Java 5+ and LLVM, all of which were published within the last 10 years. Each specification defines this term, then uses it to make formal guarantees to the programmer. One thing they have in common is that whenever there’s a synchronizes-with relationship between two operations, typically on different threads, there’s a happens-before relationship between those operations as well.
Before digging deeper, I’ll let you in on a small insight: In every synchronizes-with relationship, you should be able to identify two key ingredients, which I like to call the guard variable and the payload. The payload is the set of data being propagated between threads, while the guard variable protects access to the payload. I’ll point out these ingredients as we go.
Now let’s look at a familiar example using C++11 atomics.
A Write-Release Can Synchronize-With a Read-Acquire
Suppose we have a Message structure which is produced by one thread and consumed by another. It has the following fields:
struct Message { clock_t tick; const char* str; void* param; };
We’ll pass an instance of Message between threads by placing it in a shared global variable. This shared variable acts as the payload.
Message g_payload;
Now, there’s no portable way to fill in g_payload using a single atomic operation. So we won’t try. Instead, we’ll define a separate atomic variable, g_guard, to indicate whether g_payload is ready. As you might guess, g_guard acts as our guard variable. The guard variable must be manipulated using atomic operations, since two threads will operate on it concurrently, and one of those threads performs a write.
std::atomic<int> g_guard(0);
To pass g_payload safely between threads, we’ll use acquire and release semantics, a subject I’ve written about previously using an example very similar to this one. If you’ve already read that post, you’ll recognize the final line of the following function as a write-release operation on g_guard.
void SendTestMessage(void* param) { // Copy to shared memory using non-atomic stores. g_payload.tick = clock(); g_payload.str = "TestMessage"; g_payload.param = param; // Perform an atomic write-release to indicate that the message is ready. g_guard.store(1, std::memory_order_release); }
While the first thread calls SendTestMessage, the second thread calls TryReceiveMessage intermittently, retrying until it sees a return value of true. You’ll recognize the first line of this function as a read-acquire operation on g_guard.
bool TryReceiveMessage(Message& result) { // Perform an atomic read-acquire to check whether the message is ready. int ready = g_guard.load(std::memory_order_acquire); if (ready != 0) { // Yes. Copy from shared memory using non-atomic loads. result.tick = g_payload.tick; result.str = g_payload.str; result.param = g_payload.param; return true; } // No. return false; }
If you’ve been following this blog for a while, you already know that this example works reliably (though it’s only capable of passing a single message). I’ve already explained how acquire and release semantics introduce memory barriers, and given a detailed example of acquire and release semantics in a working C++11 application.
The C++11 standard, on the other hand, doesn’t explain anything. That’s because a standard is meant to serve as a contract or an agreement, not as a tutorial. It simply makes the promise that this example will work, without going into any further detail. The promise is made in §29.3.2 of working draft N3337:
An atomic operation A that performs a release operation on an atomic object M synchronizes with an atomic operation B that performs an acquire operation on M and takes its value from any side effect in the release sequence headed by A.
It’s worth breaking this down. In our example:
- Atomic operation A is the write-release performed in
SendTestMessage. - Atomic object M is the guard variable,
g_guard. - Atomic operation B is the read-acquire performed in
TryReceiveMessage.
As for the condition that the read-acquire must “take its value from any side effect” – let’s just say it’s sufficient for the read-acquire to read the value written by the write-release. If that happens, the synchronized-with relationship is complete, and we’ve achieved the coveted happens-before relationship between threads. Some people like to call this a synchronize-with or happens-before “edge”.
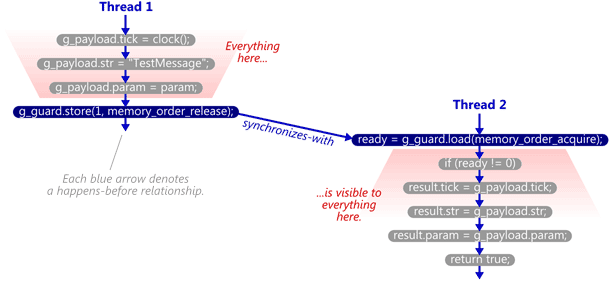
Most importantly, the standard guarantees (in §1.10.11-12) that whenever there’s a synchronizes-with edge, the happens-before relationship extends to neighboring operations, too. This includes all operations before the edge in Thread 1, and all operations after the edge in Thread 2. In the example above, it ensures that all the modifications to g_payload are visible by the time the other thread reads them.
Compiler vendors, if they wish to claim C++11 compliance, must adhere to this guarantee. At first, it might seem mysterious how they do it. But in fact, compilers fulfill this promise using the same old tricks which programmers technically had to use long before C++11 came along. For example, in this post, we saw how an ARMv7 compiler implements these operations using a pair of dmb instructions. A PowerPC compiler could implement them using lwsync, while an x86 compiler could simply use a compiler barrier, thanks to x86’s relatively strong hardware memory model.
Of course, acquire and release semantics are not unique to C++11. For example, in Java version 5 onward, every store to a volatile variable is a write-release, while every load from a volatile variable is a read-acquire. Therefore, any volatile variable in Java can act as a guard variable, and can be used to propagate a payload of any size between threads. Jeremy Manson explains this in his blog post on volatile variables in Java. He even uses a diagram very similar to the one shown above, calling it the “two cones” diagram.
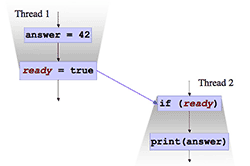
It’s a Runtime Relationship
In the previous example, we saw how the last line of SendTestMessage synchronized-with the first line of TryReceiveMessage. But don’t fall into the trap of thinking that synchronizes-with is a relationship between statements in your source code. It isn’t! It’s a relationship between operations which occur at runtime, based on those statements.
This distinction is important, and should really be obvious when you think about it. A single source code statement can execute any number of times in a running process. And if TryReceiveMessage is called too early – before Thread 1’s store to g_guard is visible – there will be no synchronizes-with relationship whatsoever.
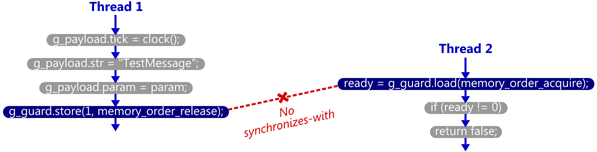
It all depends on whether the read-acquire sees the value written by the write-release, or not. That’s what the C++11 standard means when it says that atomic operation B must “take its value” from atomic operation A.
Other Ways to Achieve Synchronizes-With
Just as synchronizes-with is not only way to achieve a happens-before relationship, a pair of write-release/read-acquire operations is not the only way to achieve synchronizes-with; nor are C++11 atomics the only way to achieve acquire and release semantics. I’ve organized a few other ways into the following chart. Keep in mind that this chart is by no means exhaustive.
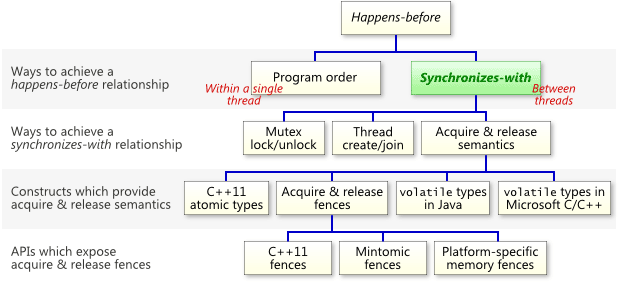
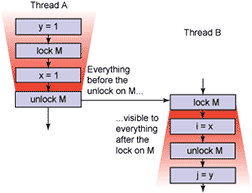
The example in this post generates lock-free code (on virtually all modern compilers and processors), but C++11 and Java expose blocking operations which introduce synchronize-with edges as well. For instance, unlocking a mutex always synchronizes-with a subsequent lock of that mutex. The language specifications are pretty clear about that one, and as programmers, we naturally expect it. You can consider the mutex itself to be the guard, and the protected variables as the payload. IBM even published an article on Java’s updated memory model in 2004 which contains a “two cones” diagram showing a pair of lock/unlock operations synchronizing-with each other.
As I’ve shown previously, acquire and release semantics can also be implemented using standalone, explicit fence instructions. In other words, it’s possible for a release fence to synchronize-with an acquire fence, provided that the right conditions are met. In fact, explicit fence instructions are the only available option in Mintomic, my own portable API for lock-free programming. I think that acquire and release fences are woefully misunderstood on the web right now, so I’ll probably write a dedicated post about them next.
The bottom line is that the synchronizes-with relationship only exists where the language and API specifications say it exists. It’s their job to define the conditions of their own guarantees at the source code level. Therefore, when using low-level ordering constraints in C++11 atomics, you can’t just slap std::memory_order_acquire and release on some operations and hope things magically work out. You need to identify which atomic variable is the guard, what’s the payload, and in which codepaths a synchronizes-with relationship is ensured.
Interestingly, the Go programming language is a bit of convention breaker. Go’s memory model is well specified, but the specification does not bother using the term “synchronizes-with” anywhere. It simply sticks with the term “happens-before”, which is just as good, since obviously, happens-before can fill the role anywhere that synchronizes-with would. Perhaps Go’s authors chose a reduced vocabulary because “synchronizes-with” is normally used to describe operations on different threads, and Go doesn’t expose the concept of threads.