Hash tables, like trees, are part of a family called associative maps, or associative arrays. They map a collection of keys to a collection of values. Associative maps are themselves part of a broader family of data structures known as containers.
Many high-level programming languages have their own set of containers built-in, and it’s not usually effective to write your own. C and C++, being native languages, are different: You can write your own containers, and it’s often very effective to do so. The Standard C++ Library provides a few, but it’s common for companies to have their own library of C++ containers, written in-house. You can also find source code for different containers floating around the web, though usually with licensing restrictions. I thought it would be interesting to compare the performance of few such containers, with an emphasis on hash tables, but with a couple of trees thrown in the mix as well.
Word Counting Benchmark
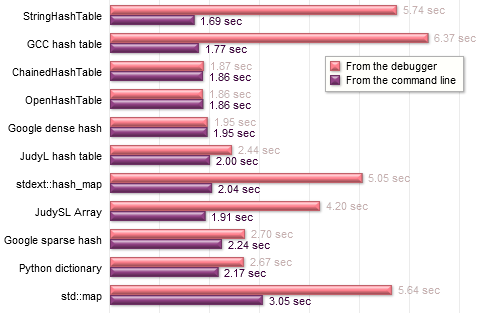
 My test program is a simple word-counting application. It reads a text file and creates a container, mapping each word to its number of occurrences. I fed this program a one million word document in which there are about 58,000 unique words, each occurring a different number of times. This results in a lot more lookups than inserts, which is a typical pattern in applications which use maps heavily, such as the gcc compiler, the Python runtime, and in many components of game development.
My test program is a simple word-counting application. It reads a text file and creates a container, mapping each word to its number of occurrences. I fed this program a one million word document in which there are about 58,000 unique words, each occurring a different number of times. This results in a lot more lookups than inserts, which is a typical pattern in applications which use maps heavily, such as the gcc compiler, the Python runtime, and in many components of game development.
You can download the source code here.
The tests were compiled in Visual Studio 2008, and ran on Windows using a Core 2 Duo E6600. I used appropriate optimization settings and disabled unnecessary features, like exception handling and iterator debugging. The entire document is preloaded in memory to avoid I/O overhead, and Doug Lea’s malloc is used for memory management. There are sure to be additional optimization opportunities in each case, but I didn’t go overboard.
 Preshing on Programming
Preshing on Programming