 Preshing on Programming
Preshing on ProgrammingHash tables, like trees, are part of a family called associative maps, or associative arrays. They map a collection of keys to a collection of values. Associative maps are themselves part of a broader family of data structures known as containers.
Many high-level programming languages have their own set of containers built-in, and it’s not usually effective to write your own. C and C++, being native languages, are different: You can write your own containers, and it’s often very effective to do so. The Standard C++ Library provides a few, but it’s common for companies to have their own library of C++ containers, written in-house. You can also find source code for different containers floating around the web, though usually with licensing restrictions. I thought it would be interesting to compare the performance of few such containers, with an emphasis on hash tables, but with a couple of trees thrown in the mix as well.
Word Counting Benchmark
 My test program is a simple word-counting application. It reads a text file and creates a container, mapping each word to its number of occurrences. I fed this program a one million word document in which there are about 58,000 unique words, each occurring a different number of times. This results in a lot more lookups than inserts, which is a typical pattern in applications which use maps heavily, such as the gcc compiler, the Python runtime, and in many components of game development.
My test program is a simple word-counting application. It reads a text file and creates a container, mapping each word to its number of occurrences. I fed this program a one million word document in which there are about 58,000 unique words, each occurring a different number of times. This results in a lot more lookups than inserts, which is a typical pattern in applications which use maps heavily, such as the gcc compiler, the Python runtime, and in many components of game development.
You can download the source code here.
The tests were compiled in Visual Studio 2008, and ran on Windows using a Core 2 Duo E6600. I used appropriate optimization settings and disabled unnecessary features, like exception handling and iterator debugging. The entire document is preloaded in memory to avoid I/O overhead, and Doug Lea’s malloc is used for memory management. There are sure to be additional optimization opportunities in each case, but I didn’t go overboard.
This is not intended to be a face-off between containers, since that would be nearly impossible to do in a way that is fair or complete. It’s more of a sampling of various approaches, followed by an attempt to understand why they stacked up the way they did.
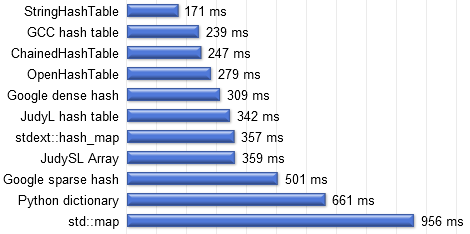
Here are the results:
The following sections describe the container used in each test, along with some analysis.
StringHashTable: 171 ms
 The fastest container was one I wrote myself. It’s just a simplification of
The fastest container was one I wrote myself. It’s just a simplification of ChainedHashTable, described a couple sections down. Like ChainedHashTable, it’s a fixed-size table with 65,536 slots and collisions resolved by chaining in an external linked list.
The only differences between this container and ChainedHashTable are that it doesn’t use templates, it doesn’t use the std::string class, and it doesn’t pass any arguments by reference. It just maps char * to int. Straightforward stuff, and the compiler is able to optimize it pretty well. For example, the signature of operator[] is just:
class StringHashTable { uint &operator[](const char *key); };
So given a char *word, we can pass it directly to operator[]. Compare the resulting disassembly to the disassembly for ChainedHashTable, a couple sections below.

GCC hash table: 239 ms
This is a hash table container written in pure C, consisting of two main files: hashtab.h and hashtab.c. It’s part of an LGPL’ed library called Libiberty, used by various GNU programs including the well-known gcc compiler.
 This hash table uses open addressing, which means it’s basically just an array, and hash collisions are resolved using other slots in the array itself. Internally, the entries are defined as
This hash table uses open addressing, which means it’s basically just an array, and hash collisions are resolved using other slots in the array itself. Internally, the entries are defined as void *, and you need to define a real data type for them to point to. Unlike the C++ containers, the compiler is not able to check for type safety, so you must be prepared to debug programming errors at runtime. I certainly hit a few doozies in my early attempts: In one case, I assumed the wrong type was passed to my hash callback. It still worked, but the running time increased by 10 seconds!
I chose the most obvious format for the entries: a struct containing a char * and an int. For the hash function, I used FNV1. (The module’s built-in htab_hash_string function actually results in 3% fewer collisions, but adds 1 or 2 ms to the total runtime of the test.) Interestingly, the array size is never a power of 2. I let it start with 65,521 available slots, but once it becomes 3/4 full, it automatically resizes to 131,071. Resizing is a slow operation (a few ms) because it needs to recompute the hash for every string, and populate a new table. But it doesn’t happen open, and doing so makes the container suitable for any amount of data.
In some ways, this module is not so much a hash table as it is a toolbox of functions which you can use to implement your own hash table. For example, the table is initialized by calling:
htab_t
htab_create_alloc (size_t size, htab_hash hash_f, htab_eq eq_f,
htab_del del_f, htab_alloc alloc_f, htab_free free_f);
sizeis the table sizehash_fis a callback function to compute the hash of an entryeq_fis a callback function to test if a given key matches a given entrydel_fis a callback to destruct an entry, in the C++ sensealloc_fandfree_fare used to allocate and free memory
The resulting overhead is pretty low, which makes it very fast, though not as fast as StringHashTable. I suppose its performance is limited by its reliance on callback functions. Of course, the advantage of callbacks is that you can re-use the common hashtab.c module for hash tables using different types of key or value – it won’t add any code size to your executable.
ChainedHashTable: 247 ms
This is a C++ hash table template I wrote and debugged in about 30 minutes. The size of the hash table is fixed at 65,536 buckets, with no resize operation. This is cheating a bit, since it’s well-suited for the data, which I knew would contain 58,000 unique words.
It uses a chaining method to handle collisions, where bucket contents are stored in an external linked list, and the list nodes are allocated in blocks of 256. I didn’t bother to implement any delete operation, but I don’t think that makes any difference for the test.
Being a template, you need to specialize it with explicit types and traits. Once again, I used FNV1 as the hash function. Since the keys need to manage their own storage, I chose std::string. The signature of operator[] this time is:
template<class Key, class Value, class Traits> class ChainedHashTable { Value &operator[](const Key &key); };
Using templates in this way gives ChainedHashTable the ability to contain any type, but it comes with a few costs: Unlike the GCC hash table, every time you specialize it with different types, you add a little bit of code size to your executable. You also need to include the entire implementation of the hash table in a header file each time it’s used by the code – exactly the kind of thing that slows down build times. Finally, the compiler output is not really optimal. In order to call operator[], the compiler first implicitly converts our char *word to a std::string using the copy constructor. This conversion requires a lot of instructions, including a loop and a function call (which potentially allocates temporary memory):
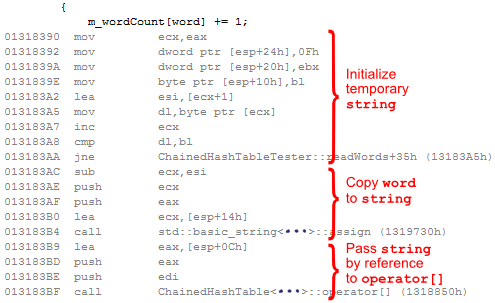
Compare that to the minimal snippet of disassembly for StringHashTable. Nonetheless, ChainedHashTable still manages to be quite fast, taking third place among our selection of containers.
OpenHashTable: 279 ms
This is another hash table template I wrote in 30 minutes, in order to try an open addressing approach, like the GCC hash table. It also supports resizing. I let it start with 65,536 available slots, and it doubles in size when it becomes 2/3 full. Again, since it’s a template, the keys are stored as std::string, and FNV1 is the hash function.
 Each slot contains a key, a value and a cache of the key’s hash. The cached hash value helps walk the probe chain more quickly, and avoids the need to recompute while resizing. Unlike GCC’s hash table, which uses double hashing,
Each slot contains a key, a value and a cache of the key’s hash. The cached hash value helps walk the probe chain more quickly, and avoids the need to recompute while resizing. Unlike GCC’s hash table, which uses double hashing, OpenHashTable uses linear probing, which means that if a slot is already in use, the operation simply searches the table sequentially for the next available free slot. Technically, linear probing leads to a greater risk of clustering, but I tried it anyway. Once again, I didn’t bother to implement any delete operation, which actually simplifies the other operations: To support open addressing with deletion, you need to make a distinction between an unused slot and a deleted slot.
With open addressing, there is a risk that the penalty of collision is more severe than with chaining, since other slots in the table get polluted as a side effect. So I was surprised it performed so well, especially with the resize operation.
Google dense hash: 309 ms
This is a C++ container originally written by Craig Silverstein at Google, maintained by a team at Google and made available as open source. You’re allowed to use it in commercial projects as long as you retain their copyright notice.
google::dense_hash_map uses open addressing with quadratic probing. By default, it resizes when it’s more than 50% full. I let it start with 65,536 slots, so it resizes once during this test. I specified std::string for the keys, and let it use the default hash function for strings, which happens to be FNV1. It seems to work as a near drop-in replacement for stdext::hash_map, except slightly faster and with bonus support for file serialization.
It pays the usual performance penalty for std::string, and another penalty for Dinkumware’s pseudo-randomizing transform, described in the next section.
JudyL hash table: 342 ms
This container basically abuses the JudyL data type from the Judy family of sparse dynamic arrays. Judy arrays were originally written Doug Baskins at Hewlett-Packard, and are made available under the LGPL. JudyL is known to efficiently map arbitrary 32-bit values to 32-bit values, so I wondered if it would perform well as a 32-bit hash table. With this approach, we don’t need to concern ourselves with the size of the hash table; Judy takes care of it adaptively.
I wrapped the idea in a template, and specified std::string as the key type, paying the usual performance penalty for string overhead. As usual, the hash function is FNV1. Collisions are handled by chaining, with linked list nodes allocated in blocks of 256, just like ChainedHashTable.
It managed to outperform Judy’s own built-in string map, JudySL. I suppose this says something about the advantage of hashing.
stdext::hash_map: 357 ms
 This is Dinkumware’s implementation of the C++
This is Dinkumware’s implementation of the C++ stdext::hash_map, as provided in Visual Studio 2008. It shares a similar API to the original hash_map, which was written at SGI due to a lack of any hash table container in the C++ Standard Template library. Like ChainedHashTable, this hash table uses chaining. In this container, though, each hash bucket is actually a pointer to a node in a single, giant doubly-linked list using std::list. It supports dynamic resizing, waiting until there is an average of 4 entries per hash bucket, then multiplying the hash table size by eight.
I dug around the source code and found that it, too, uses FNV1 by default. Strangely, after computing the hash value, it performs a “pseudo-randomizing transform” on it. This step seems rather redundant and unnecessary for FNV1, though I suppose it might help if an unwitting programmer uses a weaker hash function. Indeed, I tried removing this step later, and got a 5% speed gain. This speed gain would probably apply to Google dense hash, too.
It’s a bit slower than the previous hash tables, though pretty respectable for a Standard Library template, which doesn’t usually have a reputation for speed. Most noteworthy: It’s way faster than std::map.
JudySL array: 359 ms
JudySL is another container in the same family of Judy dynamic arrays. It’s a string map, taking a null-terminated string as a key, and mapping it to a 32-bit value. In other words, it already uses the exact data types required for this test. It’s also written in pure C.
However, JudySL is not a hash table. It’s basically a compact trie structure. It relies entirely on string comparisons (or more precisely, string fragment comparisons) to locate an entry in the trie. It still runs pretty fast, but not as fast a hash table in this test. I can’t prove it, but my gut feeling is that JudySL is just about as fast as you can get without using a hash function.
Google sparse hash: 501 ms
This is another C++ container originally written by Craig Silverstein at Google, and made available under the same terms as Google dense hash.

google::sparse_hash_map essentially uses the same algorithm as google::dense_hash_map, except that it uses a clever memory compression scheme for the array. Instead of a regular C array, it uses a google::sparsetable. To keep a long story short: When the array contents are sparse, sparse_hash_map will not ask for a lot of memory from your memory allocator. Mind you, this is a hash table, so the sparsetable does fill up quite a bit, to accomodate our 58,000 entires.
Performance was never intended to be a strong suit of this container. It strives primarily for memory efficiency of sparse arrays. That’s why it places among the slowest of the hash tables in this test.
Python dictionary: 661 ms
I’m a big Python fan, so I couldn’t resist seeing how this piece of the Python runtime stacks up. PyDictObject is written in pure C, and Python uses it internally for pretty much everything: object attributes, local variables, modules, class definitions. And of course, dictionaries.
 I tested the
I tested the PyDictObject implementation in Python 2.7.1. It consists of two main files: dictobject.h, part of the Python C API, and dictobject.c, its implementation. It’s another hash table using open addressing and a funky probe sequence for collision resolution. Once it becomes 2/3 full, it performs a resize operation, either doubling or quadrupling in size (if there are fewer than 50,000 items).
Being a Python data structure, each entry consists of a pair of Python objects. This creates considerable overhead for our C++ test application: Every char * must be converted to a Python object using PyString_FromString before either looking up or inserting into the hash table. Not only that, but just to increment the integer count, we must extract the integer value from a Python object using the PyInt_AS_LONG macro, add 1, and re-wrap the value in another Python object using PyInt_FromLong. On top of that, the Python runtime must keep track of the reference count of each object, and dynamically allocate memory for each object from the heap. Python deliberately trades off a bit of performance to gain its powerful and flexible object model.
I didn’t expect very competitive performance for this test, so I took the lazy route and simply used a precompiled python27.dll for Windows. As a result, the test application incurs DLL overhead for each call it makes to the Python C API. It also meant I couldn’t replace the memory allocator with Doug Lea’s malloc, as I had done for the other containers.
std::map: 956 ms
Finally, we’re brought to the Dinkumware implementation of the Standard C++ Library template std::map, as bundled with Visual Studio 2008. The C++ standard requires a guarantee of O(log n) running time, and Dinkumware satisfies this guarantee by implementing an ordered red-black tree. For this test, I specialize the template with a std::string, just like all the others.
It was the slowest container tested, presumably due to the overhead of having thousands of tree nodes, and multiple comparisons being performed on entire strings for each lookup.
Conclusion
This was not intended as a search for the best or fastest container. For most of the containers tested, there are imperfections in the either the implementation or the integration. The fastest container tested, StringHashTable, doesn’t even support resizing or deletion. All the C++ templates were specialized with std::string, whereas perhaps a custom string class would offer better performance. I tried to acknowledge the shortcomings in each case, and simply observe and explain the results.
Still, I feel this data strongly supports the argument that hash tables, in general, significantly outperform other associative maps. This is expected, since to maximize performance on today’s processors, algorithms must be cache-aware. Hash tables naturally avoid cache misses by virtue of simply performing fewer random memory accesses. Even the JudySL array, a very optimized, cache-aware container, was unable to match the performance of an optimized hash table in these tests.
This experiment also added some fuel to my personal dissatisfaction with templates, and the C++ language itself (which I can’t live without). It seems as though the more each container relies on C++ template classes, especially within its own implementation, the more performance is sacrificed. This trend emerges when you look at the relative performance of StringHashTable, ChainedHashTable, Google dense hash and stdext::hash_map. There’s no denying that once a given C++ template exists in a codebase, it’s incredibly productive and convenient to use. Still, I dream of a language even more expressive than C++ in which it is easy to write containers that perform as well as StringHashTable.