 Preshing on Programming
Preshing on ProgrammingA lock-free hash table is a double-edged sword. There are applications where it can provide a performance improvement that would be impossible to achieve otherwise. The downside is that it’s complicated.
The first working lock-free hash table I heard about was written in Java by Dr. Cliff Click. He released the source code back in 2007 and gave a presentation about it at Google that same year. When I first watched that presentation, I’ll admit, I didn’t understand most of it. The main conclusion I took away from it was that Dr. Cliff Click must be some kind of wizard.

Luckily, six years has given me enough time to (mostly) catch up to Cliff on this subject. It turns out that you don’t have to be a wizard to understand and implement a very basic, but perfectly functional, lock-free hash table. I’ll share the source code for one here. I’m pretty sure that anyone with experience writing multithreaded C++, and a willingness to comb through previous information on this blog, can fully understand it.
This hash table is written using Mintomic, a portable library for lock-free programming in C/C++ which I released last month. It compiles & runs on several x86/64, PowerPC and ARM-based platforms straight out of the box. And since every Mintomic function has an equivalent in C++11, converting this hash table to C++11 is a straightforward exercise.
Limitations
As programmers, our usual instinct is to write data structures that are as general-purpose and reusable as possible. This is not a bad thing, but it can hinder us if we turn it into a goal right out of the gate. For this post, I’ve gone to the other extreme, implementing the most limited, special-purpose lock-free hash table I could get away with. Here are its design constraints:
- Maps 32-bit integer keys to 32-bit integer values only.
- All keys must be non-zero.
- All values must be non-zero.
- The table has a fixed maximum number of entries it can hold, which must be a power of two.
- The only available operations are
SetItemandGetItem. - There is no delete operation.
Rest assured, once you’ve mastered the limited form of this lock-free hash table, it’s possible to remove each of the above limitations incrementally, without fundamentally changing the approach.
The Approach
There are many ways to implement a hash table. The approach I’ve chosen here is actually just a simple modification of the ArrayOfItems class described in my previous post, A Lock-Free… Linear Search? I strongly recommend reviewing that post before continuing.
Like ArrayOfItems, this hash table class, which I’ve named HashTable1, is implemented using a single, giant array of key/value pairs.
struct Entry
{
mint_atomic32_t key;
mint_atomic32_t value;
};
Entry *m_entries;
In HashTable1, there are no linked lists to resolve hash collisions outside the table; there is only the array itself. A zero key in the array designates a free entry, and the array is initially all zeros. And just like ArrayOfItems, items in HashTable1 are inserted and located by performing a linear search.
The only difference between ArrayOfItems and HashTable1 is that, while ArrayOfItems always begins its linear search at index 0, HashTable1 instead begins each linear search at an index determined by hashing the key. The hash function I chose is MurmurHash3’s integer finalizer, since it’s fast and scrambles integer inputs quite nicely.
inline static uint32_t integerHash(uint32_t h) { h ^= h >> 16; h *= 0x85ebca6b; h ^= h >> 13; h *= 0xc2b2ae35; h ^= h >> 16; return h; }
As a result, each time we call SetItem or GetItem using the same key, it will begin the linear search at the same index, but when different keys are passed in, it will tend to begin the search at a completely different index. In this way, the items end up much more “spread out” around the array than they are in ArrayOfItems, and it remains safe to call SetItem and GetItem from multiple threads in parallel.
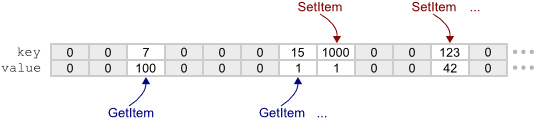
HashTable1 uses a circular search, which means that if SetItem or GetItem reaches the end of the array, it simply wraps back around to index 0 and continues searching. As long as the array never fills completely, every search is guaranteed to finish either by locating the desired key, or by locating an entry whose key is zero, which means that the desired key does not exist in the hash table. This technique is referred to as open addressing with linear probing, and in my opinion, it’s the most lock-free-friendly hash table technique there is. Indeed, this is the same technique Dr. Click uses in his Java-based lock-free hash table.
The Code
Here’s a function which implements SetItem. It scans through the array and stores the item in the first entry whose existing key is either 0, or matches the desired key. It’s nearly identical to the code for ArrayOfItems::SetItem, as described in the previous post. The only differences are the integer hash and the bitwise-and on idx, which keeps it within the array boundaries.
void HashTable1::SetItem(uint32_t key, uint32_t value) { for (uint32_t idx = integerHash(key);; idx++) { idx &= m_arraySize - 1; uint32_t prevKey = mint_compare_exchange_strong_32_relaxed(&m_entries[idx].key, 0, key); if ((prevKey == 0) || (prevKey == key)) { mint_store_32_relaxed(&m_entries[idx].value, value); return; } } }
The code for GetItem is nearly identical to ArrayOfItems::GetItem as well, except for the same changes.
uint32_t HashTable1::GetItem(uint32_t key)
{
for (uint32_t idx = integerHash(key);; idx++)
{
idx &= m_arraySize - 1;
uint32_t probedKey = mint_load_32_relaxed(&m_entries[idx].key);
if (probedKey == key)
return mint_load_32_relaxed(&m_entries[idx].value);
if (probedKey == 0)
return 0;
}
}
Both of the above functions are thread-safe and lock-free for the same reasons as in ArrayOfItems: The array contents are manipulated using atomic library functions, entries are assigned by performing a compare-and-swap (CAS) on the key, and the whole thing is resilient against memory reordering. Again, review that post for a more complete discussion.
Finally, just like in the previous post, we can optimize SetItem by first checking whether the CAS is necessary, and avoiding it when possible. This optimization makes the sample application, described below, run about 20% faster.
void HashTable1::SetItem(uint32_t key, uint32_t value) { for (uint32_t idx = integerHash(key);; idx++) { idx &= m_arraySize - 1; // Load the key that was there. uint32_t probedKey = mint_load_32_relaxed(&m_entries[idx].key); if (probedKey != key) { // The entry was either free, or contains another key. if (probedKey != 0) continue; // Usually, it contains another key. Keep probing. // The entry was free. Now let's try to take it using a CAS. uint32_t prevKey = mint_compare_exchange_strong_32_relaxed(&m_entries[idx].key, 0, key); if ((prevKey != 0) && (prevKey != key)) continue; // Another thread just stole it from underneath us. // Either we just added the key, or another thread did. } // Store the value in this array entry. mint_store_32_relaxed(&m_entries[idx].value, value); return; } }
And there you have it! The world’s simplest lock-free hash table. Here are direct links to the source and header.
One word of caution: As with ArrayOfItems, all operations on HashTable1 effectively come with relaxed memory ordering constraints. Therefore, if you publicize the availability of some data to other threads by storing a flag in HashTable1, you must place release semantics on that store by issuing a release fence immediately beforehand. Similarly, the call to GetItem would need an acquire fence in the receiving thread.
// Shared variables char message[256]; HashTable1 collection; void PublishMessage() { // Write to shared memory non-atomically. strcpy(message, "I pity the fool!"); // Release fence: The only way to safely pass non-atomic data between threads using Mintomic. mint_thread_fence_release(); // Set a flag to indicate to other threads that the message is ready. collection.SetItem(SHARED_FLAG_KEY, 1) }
Sample Application
To kick the tires of HashTable1, I’ve put together another sample application which is very similar to the one from the previous post. It alternates between two experiments: One where each of two threads adds 6000 items with unique keys, and another where each thread adds 12000 items using the same keys but different values.
All the code is on GitHub, so you can compile and run it yourself. See the README.md file for build instructions.
As long as the hash table never gets too full – let’s say, with fewer than 80% of the array entries in use – HashTable1 is an excellent performer. I should probably back up this claim with some benchmarks, but based on previous experience benchmarking single-threaded hash tables, I’m willing to bet you can’t implement a more efficient lock-free hash table than HashTable1. That might seem surprising when you consider that ArrayOfItems, on which it’s based, is a terrible performer. Of course, as with any hash table, there’s always a non-zero risk of hashing a large number of keys to the same array index, and degrading back to the performance of ArrayOfItems. But with a large table and good hash function like MurmurHash3’s integer finalizer, that’s an extremely unlikely scenario.
I’ve used lock-free tables similar to this one in real projects. In one case, a game I worked on was bottlenecked by heavy contention on a shared lock whenever the memory tracker was enabled. After migrating to a lock-free hash table, the worst-case framerate of the game improved from 4 FPS to 10 FPS when running in this mode.