 Preshing on Programming
Preshing on ProgrammingConsider the lowly text file.

This text file can take on a surprising number of different formats. The text could be encoded as ASCII, UTF-8, UTF-16 (little or big-endian), Windows-1252, Shift JIS, or any of dozens of other encodings. The file may or may not begin with a byte order mark (BOM). Lines of text could be terminated with a linefeed character \n (typical on UNIX), a CRLF sequence \r\n (typical on Windows) or, if the file was created on an older system, some other character sequence.
Sometimes it’s impossible to determine the encoding used by a particular text file. For example, suppose a file contains the following bytes:
A2 C2 A2 C2 A2 C2
This could be:
- a UTF-8 file containing “¢¢¢”
- a little-endian UTF-16 (or UCS-2) file containing “ꋂꋂꋂ”
- a big-endian UTF-16 file containing “슢슢슢”
- a Windows-1252 file containing “¢¢¢”
That’s obviously an artificial example, but the point is that text files are inherently ambiguous. This poses a challenge to software that loads text.
It’s a problem that has been around for a while. Fortunately, the text file landscape has gotten simpler over time, with UTF-8 winning out over other character encodings. More than 95% of the Internet is now delivered using UTF-8. It’s impressive how quickly that number has changed; it was less than 10% as recently as 2006.
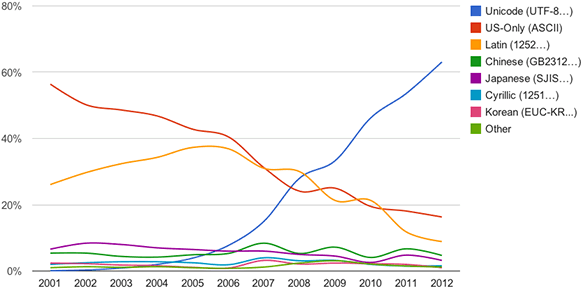
UTF-8 hasn’t taken over the world just yet, though. The Windows Registry editor, for example, still saves text files as UTF-16. When writing a text file from Python, the default encoding is platform-dependent; on my Windows PC, it’s Windows-1252. In other words, the ambiguity problem still exists today. And even if a text file is encoded in UTF-8, there are still variations in format, since the file may or may not start with a BOM and could use either UNIX-style or Windows-style line endings.
How the Plywood C++ Framework Loads Text
Plywood is a cross-platform open-source C++ framework I released two months ago. When opening a text file using Plywood, you have a couple of options:
- If you know the exact format of the text file ahead of time, you can call
FileSystem::openTextForRead(), passing the expected format in aTextFormatstructure. - If you don’t know the exact format, you can call
FileSystem::openTextForReadAutodetect(), which will attempt to detect the format automatically and return it to you.
The input stream returned from these functions never starts with a BOM, is always encoded in UTF-8, and always terminates each line of input with a single carriage return \n, regardless of the input file’s original format. Conversion is performed on the fly if needed. This allows Plywood applications to work with a single encoding internally.
Automatic Format Detection
Here’s how Plywood’s automatic text format detection currently works:
Plywood analyzes up to the first 4KB of the input file in order to guess its format. The first two checks handle the vast majority of text files I’ve encountered. There are lots of invalid byte sequences in UTF-8, so if a text file can be decoded as UTF-8 and doesn’t contain any control codes, then it’s almost certainly a UTF-8 file. (A control code is considered to be any code point less than 32 except for tab, linefeed and carriage return.)
It’s only when we enter the bottom half of the flowchart that some guesswork begins to happen. First, Plywood decides whether it’s better to interpret the file as UTF-8 or as plain bytes. This is meant to catch, for example, text encoded in Windows-1252 that uses accented characters. In Windows-1252, the French word détail is encoded as 64 E9 74 61 69 6C, which triggers a UTF-8 decoding error since UTF-8 expects E9 to be followed be a byte in the range 80 - BF. After a certain number of such errors, Plywood will favor plain bytes over UTF-8.
Scoring System
After that, Plywood attempts to decode the same data using the 8-bit format, little-endian UTF-16 and big-endian UTF-16. It calculates a score for each encoding as follows:
- Each whitespace character decoded is worth +2.5 points. Whitespace is very helpful to identify encodings, since UTF-8 whitespace can’t be recognized in UTF-16, and UTF-16 whitespace contains control codes when interpreted in an 8-bit encoding.
- ASCII characters are worth +1 point each, except for control codes.
- Decoding errors incur a penalty of -100 points.
- Control codes incur a penalty of -50 points.
- Code points greater than U+FFFF are worth +5 points, since the odds of encountering such characters in random data is low no matter what the encoding. This includes emojis.
Scores are divided by the total number of characters decoded, and the best score is chosen. If you’re wondering where these point values came from, I made them up! They’re probably not optimal yet.
The algorithm has other weaknesses. Plywood doesn’t yet know how to decode arbitrary 8-bit decodings. Currently, it interprets every 8-bit text file that isn’t UTF-8 as Windows-1252. It also doesn’t support Shift JIS at this time. The good news is that Plywood is an open source project on GitHub, which means that improvements can published as soon as they’re developed.
The Test Suite
In Plywood’s GitHub repository, you’ll find a folder that contains 50 different text files using a variety of formats. All of these files are identified and loaded correctly using FileSystem::openTextForReadAutodetect().
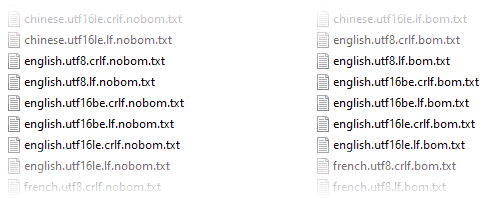
A lot of modern text editors perform automatic format detection, just like Plywood. Out of curiosity, I tried opening this set of text files in a few editors:
- Notepad++ correctly detected the format of 38 out of 50 files. It fails on all UTF-16 files that are missing a BOM except for little-endian files that mostly consist of ASCII characters.
- Sublime Text correctly detected the format of 42 files. When text consists mostly of ASCII, it guesses correctly no matter what the encoding.
- Visual Studio Code correctly detected the format of 40 files. It’s like Sublime Text, but fails on Windows-1252 files containing accented characters.
- And perhaps most impressively, Windows Notepad correctly detected the format of a whopping 42 files! It guesses correctly on all little-endian UTF-16 files without BOMs, but fails on all big-endian UTF-16 files without BOMs.
Admittedly, this wasn’t a fair contest, since the entire test suite is hand-made for Plywood. And most of the time, when an editor failed, it was on a UTF-16 file that was missing a BOM, which seems to be a rare format – none of the editors allows you to save such a file.
It’s worth mentioning that these text editors were the inspiration for Plywood’s autodetection strategy in the first place. Working with Unicode has always been difficult in C++ – the situation is bad enough the standard C++ committee recently formed a study group dedicated to improving it. Meanwhile, I’ve always wondered: Why can’t loading text in C++ be as simple as it is in a modern text editor?
If you’d like to improve Plywood in any of the ways mentioned in this post, feel free to get involved on GitHub or in the Discord server. And if you only need the source code that detects text encodings, but don’t want to adopt Plywood itself, I get it! Feel free to copy the source code however you see fit – everything is MIT licensed.