 Preshing on Programming
Preshing on ProgrammingAs I explained previously, there are two valid ways for a C++11 compiler to implement memory_order_consume: an efficient strategy and a heavy one. In the heavy strategy, the compiler simply treats memory_order_consume as an alias for memory_order_acquire. The heavy strategy is not what the designers of memory_order_consume had in mind, but technically, it’s still compliant with the C++11 standard.
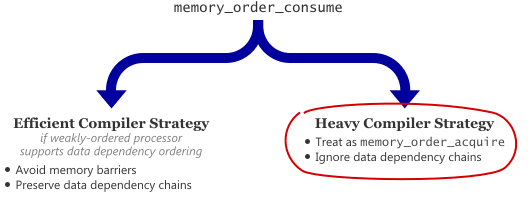
There’s a somewhat common misconception that all current C++11 compilers use the heavy strategy. I certainly had that impression until recently, and others I spoke to at CppCon 2014 seemed to have that impression as well.
This belief turns out not to be true: GCC does not always use the heavy strategy (yet). GCC 4.9.2 actually has a bug in its implementation of memory_order_consume, as described in this GCC bug report. I was rather surprised to learn that, since it contradicted my own experience with GCC 4.8.3, in which the PowerPC compiler appeared to use the heavy strategy correctly.
I decided to verify the bug on my own, which is why I recently took an interest in building GCC cross-compilers. This post will explain the bug and document the process of patching the compiler.
An Example That Illustrates the Compiler Bug
Imagine a bunch of threads repeatedly calling the following read function:
#include <atomic>
std::atomic<int> Guard(0);
int Payload[1] = { 0xbadf00d };
int read()
{
int f = Guard.load(std::memory_order_consume); // load-consume
if (f != 0)
return Payload[f - f]; // plain load from Payload[f - f]
return 0;
}
At some point, another thread comes along and calls write:
int write()
{
Payload[0] = 42; // plain store to Payload[0]
Guard.store(1, std::memory_order_release); // store-release
}
If the compiler is fully compliant with the current C++11 standard, then there are only two possible return values from read: 0 or 42. The outcome depends on the value seen by the load-consume highlighted above. If the load-consume sees 0, then obviously, read will return 0. If the load-consume sees 1, then according to the rules of the standard, the plain store Payload[0] = 42 must be visible to the plain load Payload[f - f], and read must return 42.
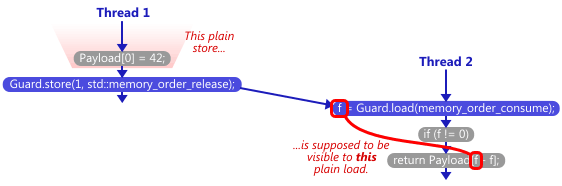
As I’ve already explained, memory_order_consume is meant to provide ordering guarantees that are similar to those of memory_order_acquire, only restricted to code that lies along the load-consume’s dependency chain at the source code level. In other words, the load-consume must carry-a-dependency to the source code statements we want ordered.
In this example, we are admittedly abusing C++11’s definition of carry-a-dependency by using f in an expression that cancels it out (f - f). Nonetheless, we are still technically playing by the standard’s current rules, and thus, its ordering guarantees should still apply.
Compiling for AArch64
The compiler bug report mentions AArch64, a new 64-bit instruction set supported by the latest ARM processors. Conveniently enough, I described how to build a GCC cross-compiler for AArch64 in the previous post. Let’s use that cross-compiler to compile the above code and examine the assembly listing for read:
$ aarch64-linux-g++ -std=c++11 -O2 -S consumetest.cpp
$ cat consumetest.s
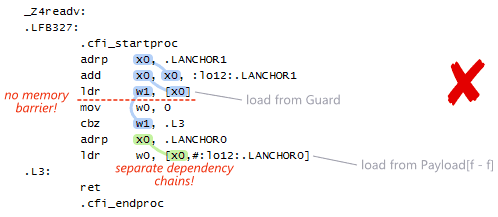
This machine code is flawed. AArch64 is a weakly-ordered CPU architecture that preserves data dependency ordering, and yet neither compiler strategy has been taken:
- No heavy strategy: There is no memory barrier instruction between the load from
Guardand the load fromPayload[f - f]. The load-consume has not been promoted to a load-acquire. - No efficient strategy: There is no dependency chain connecting the two loads at the machine code level. I’ve highlighted the two machine-level dependency chains above, in blue and green. As you can see, the two loads lie along separate chains.
As a result, the processor is free to reorder the loads at runtime so that the second load sees an older value than the first. There is a very real possibility that read will return 0xbadf00d, the initial value of Payload[0], even though the C++ standard forbids it.
Patching the Cross-Compiler
Andrew Macleod posted a patch for this issue in the bug report. His patch adds the following lines near the end of the get_memmodel function in gcc/builtins.c:
/* Workaround for Bugzilla 59448. GCC doesn't track consume properly, so
be conservative and promote consume to acquire. */
if (val == MEMMODEL_CONSUME)
val = MEMMODEL_ACQUIRE;
Let’s apply this patch and build a new cross-compiler.
$ cd gcc-4.9.2/gcc
$ wget -qO- https://gcc.gnu.org/bugzilla/attachment.cgi?id=33831 | patch
$ cd ../../build-gcc
$ make
$ make install
$ cd ..
Now let’s compile the same source code as before:
$ aarch64-linux-g++ -std=c++11 -O2 -S consumetest.cpp
$ cat consumetest.s
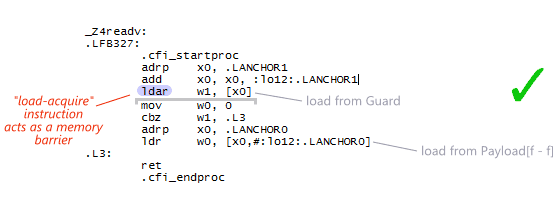
This time, the generated assembly is valid. The compiler now implements the load-consume from Guard using ldar, a new AArch64 instruction that provides acquire semantics. This instruction acts as a memory barrier on the load itself, ensuring that the load will be completed before all subsequent loads and stores (among other things). In other words, our AArch64 cross-compiler now implements the “heavy” strategy correctly.
This Bug Doesn’t Happen on PowerPC
Interestingly, if you compile the same example for PowerPC, there is no bug. This is using the same GCC version 4.9.2 without Andrew’s patch applied:
$ powerpc-linux-g++ -std=c++11 -O2 -S consumetest.cpp
$ cat consumetest.s
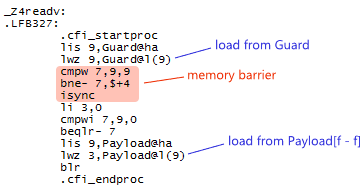
The PowerPC cross-compiler appears to implement the “heavy” strategy correctly, promoting consume to acquire and emitting the necessary memory barrier instructions. Why does the PowerPC cross-compiler work in this case, but not the AArch64 cross-compiler? One hint lies in GCC’s machine description (MD) files. GCC uses these MD files in its final stage of compilation, after optimization, when it converts its intermediate RTL format to a native assembly code listing. Among the AArch64 MD files, in gcc-4.9.2/gcc/config/aarch64/atomics.md, you’ll currently find the following:
if (model == MEMMODEL_RELAXED
|| model == MEMMODEL_CONSUME
|| model == MEMMODEL_RELEASE)
return "ldr<atomic_sfx>\t%<w>0, %1";
else
return "ldar<atomic_sfx>\t%<w>0, %1";
Meanwhile, among PowerPC’s MD files, in gcc-4.9.2/gcc/config/rs6000/sync.md, you’ll find:
switch (model)
{
case MEMMODEL_RELAXED:
break;
case MEMMODEL_CONSUME:
case MEMMODEL_ACQUIRE:
case MEMMODEL_SEQ_CST:
emit_insn (gen_loadsync_<mode> (operands[0]));
break;
Based on the above, it seems that the AArch64 cross-compiler currently treats consume the same as relaxed at the final stage of compilation, whereas the PowerPC cross-compiler treats consume the same as acquire at the final stage. Indeed, if you move case MEMMODEL_CONSUME: one line earlier in the PowerPC MD file, you can reproduce the bug on PowerPC, too.
Andrew’s patch appears to make all compilers treat consume the same as acquire at an earlier stage of compilation.
The Uncertain Future of memory_order_consume
It’s fair to call memory_order_consume an obscure subject, and the current status of GCC support reflects that. The C++ standard committee is wondering what to do with memory_order_consume in future revisions of C++.
My opinion is that the definition of carries-a-dependency should be narrowed to require that different return values from a load-consume result in different behavior for any dependent statements that are executed. Let’s face it: Using f - f as a dependency is nonsense, and narrowing the definition would free the compiler from having to support such nonsense “dependencies” if it chooses to implement the efficient strategy. This idea was first proposed by Torvald Riegel in the Linux Kernel Mailing List and is captured among various alternatives described in Paul McKenney’s proposal N4036.