 Preshing on Programming
Preshing on ProgrammingIn the C++11 standard atomic library, most functions accept a memory_order argument:
enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
};
The above values are referred to as memory ordering constraints. Each of them has its intended purpose. Among them, memory_order_consume is probably the least well-understood. It’s the most complicated ordering constraint, and it offers the least reward for using it correctly. Nonetheless, there it is, tempting the curious programmer to make sense of it – if only to unlock its dark, mysterious secrets. That’s exactly what this post aims to do.
First, let’s get our terminology straight: An operation that uses memory_order_consume is said to have consume semantics. We call such operations consume operations.
Perhaps the most valuable observation about memory_order_consume is that you can always safely replace it with memory_order_acquire. That’s because acquire operations provide all of the guarantees of consume operations, and then some. In other words, acquire is stronger.
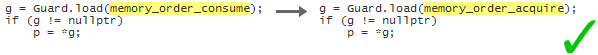
Both consume and acquire serve the same purpose: To help pass non-atomic information safely between threads. And just like acquire operations, a consume operation must be combined with a release operation in another thread. The main difference is that there are fewer cases where consume operations are legal. In return for the inconvenience, consume operations are meant to be more efficient on some platforms. I’ll illustrate all of these points using an example.
A Quick Recap of Acquire and Release Semantics
This example will begin by passing a small amount of data between threads using acquire and release semantics. Later, we’ll modify it to use consume semantics instead.
First, let’s declare two shared variables. Guard is a C++11 atomic integer, while Payload is just a plain int. Both variables are initially zero.
atomic<int> Guard(0); int Payload = 0;
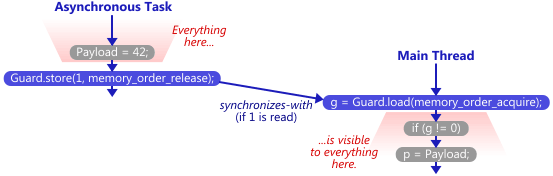
The main thread sits in a loop, repeatedly attempting the following sequence of reads. Basically, the purpose of Guard is to protect access to Payload using acquire semantics. The main thread won’t attempt to read from Payload until Guard is non-zero.
g = Guard.load(memory_order_acquire); if (g != 0) p = Payload;
At some point, an asynchronous task (running in another thread) comes along, assigns 42 to Payload, then sets Guard to 1 with release semantics.
Payload = 42; Guard.store(1, memory_order_release);
Readers should be familiar with this pattern by now; we’ve seen it several times before on this blog. Once the asynchronous task writes to Guard, and the main thread reads it, it means that the write-release synchronized-with the read-acquire. In that case, we are guaranteed that p will equal 42, no matter what platform we run this example on.
Here, we’ve used acquire and release semantics to pass a simple non-atomic integer Payload between threads, but the pattern works equally well with larger payloads, as demonstrated in previous posts.
The Cost of Acquire Semantics
To measure the cost of memory_order_acquire, I compiled and ran the above example on three different multicore systems. For each architecture, I chose the compiler with the best available support for C++11 atomics. You’ll find the complete source code on GitHub.

Let’s look at the resulting machine code around the read-acquire:
g = Guard.load(memory_order_acquire); if (g != 0) p = Payload;
Intel x86-64
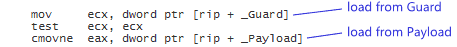
On Intel x86-64, the Clang compiler generates compact machine code for this example – one machine instruction per line of C++ source code. This family of processors features a strong memory model, so the compiler doesn’t need to emit special memory barrier instructions to implement the read-acquire. It just has to keep the machine instructions in the correct order.
PowerPC

PowerPC is a weakly-ordered CPU, which means that the compiler must emit memory barrier instructions to guarantee acquire semantics on multicore systems. In this case, GCC used a sequence of three instructions, cmp;bne;isync, as recommended here. (A single lwsync instruction would have done the job, too.)
ARMv7

ARM is also a weakly-ordered CPU, so again, the compiler must emit memory barrier instructions to guarantee acquire semantics on multicore. On ARMv7, dmb ish is the best available instruction, despite being a full memory barrier.
Here are the timings for each iteration of our example’s main loop, running on the test machines shown above:
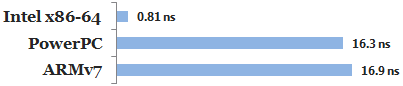
On PowerPC and ARMv7, the memory barrier instructions impose a performance penalty, but they are necessary for this example to work. In fact, if you delete all dmb ish instructions from the ARMv7 machine code, but leave everything else the same, memory reordering can be directly observed on the iPhone 4S.
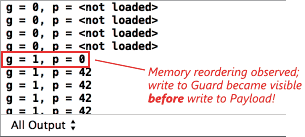
Data Dependency Ordering
Now, I’ve said that PowerPC and ARM are weakly-ordered CPUs, but in fact, there are some cases where they do enforce memory ordering at the machine instruction level without the need for explicit memory barrier instructions. Specifically, these processors always preserve memory ordering between data-dependent instructions.
Two machine instructions, executed in the same thread, are data-dependent whenever the first instruction outputs a value and the second instruction uses that value as input. The value could be written to register, as in the following PowerPC listing. Here, the first instruction loads a value into r9, and the second instruction treats r9 as a pointer for the next load:
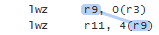
Because there is a data dependency between these two instructions, the loads will be performed in-order.
You may think that’s obvious. After all, how can the second instruction know which address to load from before the first instruction loads r9? Obviously, it can’t. Keep in mind, though, that it’s also possible for the load instructions to read from different cache lines. If another CPU core is modifying memory concurrently, and the second instruction’s cache line is not as up-to-date as the first, that would result in memory reordering, too! PowerPC goes the extra mile to avoid that, keeping each cache line fresh enough to ensure data dependency ordering is always preserved.
Data dependencies are not only established through registers; they can also be established through memory locations. In this listing, the first instruction writes a value to memory, and the second instruction reads that value back, establishing a data dependency between the two:
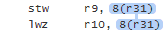
When multiple instructions are data-dependent on each other, we call it a data dependency chain. In the following PowerPC listing, there are two independent data dependency chains:

Data dependency ordering guarantees that all memory accesses performed along a single chain will be performed in-order. For example, in the above listing, memory ordering between the first blue load and last blue load will be preserved, and memory ordering between the first green load and last green load will be preserved. On the other hand, no guarantees are made about independent chains! So, the first blue load could still effectively happen after any of the green loads.
There are other processor families that preserve data dependency ordering, too. Itanium, PA-RISC, SPARC (in RMO mode) and zSeries all respect data dependency ordering at the machine instruction level. In fact, the only known weakly-ordered processor that does not preserve data dependency ordering is the DEC Alpha.
It goes without saying that strongly-ordered CPUs, such as Intel x86, x86-64 and SPARC (in TSO mode), also respect data dependency ordering.
Consume Semantics Are Designed to Exploit That
When you use consume semantics, you’re basically trying to make the compiler exploit data dependencies on all those processor families. That’s why, in general, it’s not enough to simply change memory_order_acquire to memory_order_consume. You must also make sure there are data dependency chains at the C++ source code level.

At the source code level, a dependency chain is a sequence of expressions whose evaluations all carry-a-dependency to each another. Carries-a-dependency is defined in §1.10.9 of the C++11 standard. For the most part, it just says that one evaluation carries-a-dependency to another if the value of the first is used as an operand of the second. It’s kind of like the language-level version of a machine-level data dependency. (There is actually a strict set of conditions for what constitutes carrying-a-dependency in C++11 and what does not, but I won’t go into the details here.)
Now, let’s go ahead and modify the original example to use consume semantics. First, we’ll change the type of Guard from atomic<int> to atomic<int*>:
atomic<int*> Guard(nullptr); int Payload = 0;
We do that because, in the asynchronous task, we want to store a pointer to Payload to indicate that the payload is ready:
Payload = 42; Guard.store(&Payload, memory_order_release);
Finally, in the main thread, we replace memory_order_acquire with memory_order_consume, and we load p indirectly via the pointer obtained by g. Loading from g, rather than reading directly from Payload, is key! It makes the first line of code carry-a-dependency to the third line, which is crucial to using consume semantics correctly in this example:
g = Guard.load(memory_order_consume); if (g != nullptr) p = *g;
You can view the complete source code on GitHub.
Now, this modified example works every bit as reliably as the original example. Once the asynchronous task writes to Guard, and the main thread reads it, the C++11 standard guarantees that p will equal 42, no matter what platform we run it on. The difference is that, this time, we don’t have a synchronizes-with relationship anywhere. What we have this time is called a dependency-ordered-before relationship.
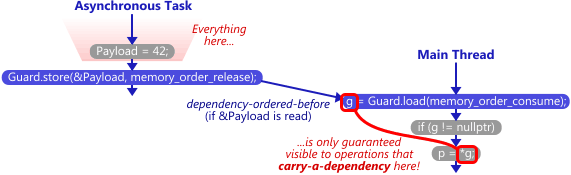
In any dependency-ordered-before relationship, there’s a dependency chain starting at the consume operation, and all memory operations performed before the write-release are guaranteed to be visible to that chain.
The Value of Consume Semantics
Now, let’s take a look at some machine code for our modified example using consume semantics.
Intel x86-64
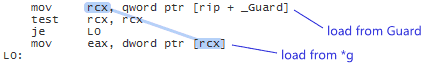
This machine code loads Guard into register rcx, then, if rcx is not null, uses rcx to load the payload, thus creating a data dependency between the two load instructions. The data dependency doesn’t really make a difference here, though. x86-64’s strong memory model already guarantees that loads are performed in-order, even if there isn’t a data dependency.
PowerPC

This machine code loads Guard into register r9, then uses r9 to load the payload, thus creating a data dependency between the two load instructions. And it helps – this data dependency lets us completely avoid the cmp;bne;isync sequence of instructions that formed a memory barrier in the original example, while still ensuring that the two loads are performed in-order.
ARMv7
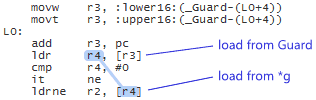
This machine code loads Guard into register r4, then uses r4 to load the payload, thus creating a data dependency between the two load instructions. This data dependency lets us completely avoid the dmb ish instruction that was present in the original example, while still ensuring that the two loads are performed in-order.
Finally, here are new timings for each iteration of the main loop, using the assembly listings I just showed you:
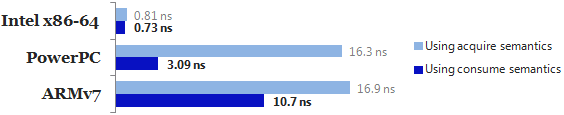
Unsurprisingly, consume semantics make little difference on Intel x86-64, but they make a huge difference on PowerPC and a significant difference on ARMv7, by allowing us to eliminate costly memory barriers. Keep in mind, of course, that these are microbenchmarks. In a real application, the performance gain would depend on the frequency of acquire operations being performed.
One real-world example of a codebase that uses this technique – exploiting data dependency ordering to avoid memory barriers – is the Linux kernel. Linux provides an implementation of read-copy-update (RCU), which is suitable for building data structures that are read frequently from multiple threads, but modified infrequently. As of this writing, however, Linux doesn’t actually use C++11 (or C11) consume semantics to eliminate those memory barriers. Instead, it relies on its own API and conventions. Indeed, RCU served as motivation for adding consume semantics to C++11 in the first place.
Today’s Compiler Support is Lacking
I have a confession to make. Those assembly code listings I just showed you for PowerPC and ARMv7? Those were fabricated. Sorry, but GCC 4.8.3 and Clang 4.6 don’t actually generate that machine code for consume operations! I know, it’s a little disappointing. But the goal of this post was to show you the purpose of memory_order_consume. Unfortunately, the reality is that today’s compilers do not yet play along.
You see, compilers have a choice of two strategies for implementing memory_order_consume on weakly-ordered processors: an efficient strategy and a heavy one. The efficient strategy is the one described in this post. If the processor respects data dependency ordering, the compiler can refrain from emitting memory barrier instructions, as long as it outputs a machine-level dependency chain for each source-level dependency chain that begins at a consume operation. In the heavy strategy, the compiler simply treats memory_order_consume as if it were memory_order_acquire, and ignores dependency chains altogether.
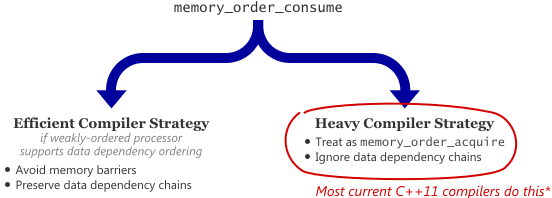
Current versions of GCC and Clang/LLVM use the heavy strategy, all the time (*except for a known bug in the current GCC). As a result, if you compile memory_order_consume for PowerPC or ARMv7 using today’s compilers, you’ll end up with unnecessary memory barrier instructions, which defeats the whole point.
It turns out that it’s difficult for compiler writers to implement the efficient strategy while adhering to the letter of the current C++11 specification. There are some proposals being put forth to improve the specification, with the goal of making it easier for compilers to support. I won’t go into the details here; that’s a whole other potential blog post.
If compilers did implement the efficient strategy, you could use it to optimize lazy initialization via double-checked locking, lock-free hash tables with non-trivial types, lock-free stacks and lock-free queues. Mind you, the performance gains would only be realized on specific processor families, and are likely to be negligible if the load-consume is performed fewer than, say, 100000 times per second.