 Preshing on Programming
Preshing on ProgrammingIn multithreaded programming, it’s important to make threads wait. They must wait for exclusive access to a resource. They must wait when there’s no work available. One way to make threads wait – and put them to sleep inside the kernel, so that they no longer take any CPU time – is with a semaphore.
I used to think semaphores were strange and old-fashioned. They were invented by Edsger Dijkstra back in the early 1960s, before anyone had done much multithreaded programming, or much programming at all, for that matter. I knew that a semaphore could keep track of available units of a resource, or function as a clunky kind of mutex, but that seemed to be about it.
My opinion changed once I realized that, using only semaphores and atomic operations, it’s possible to implement all of the following primitives:
- A Lightweight Mutex
- A Lightweight Auto-Reset Event Object
- A Lightweight Read-Write Lock
- Another Solution to the Dining Philosophers Problem
- A Lightweight Semaphore With Partial Spinning
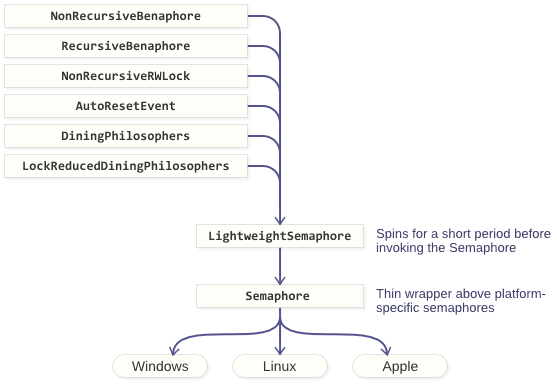
Not only that, but these implementations share some desirable properties. They’re lightweight, in the sense that some operations happen entirely in userspace, and they can (optionally) spin for a short period before sleeping in the kernel. You’ll find all of the C++11 source code on GitHub. Since the standard C++11 library does not include semaphores, I’ve also provided a portable Semaphore class that maps directly to native semaphores on Windows, MacOS, iOS, Linux and other POSIX environments. You should be able to drop any of these primitives into almost any existing C++11 project.
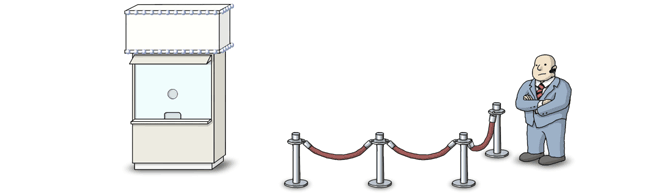
A Semaphore Is Like a Bouncer
Imagine a set of waiting threads, lined up in a queue – much like a lineup in front of a busy nightclub or theatre. A semaphore is like a bouncer at the front of the lineup. He only allows threads to proceed when instructed to do so.
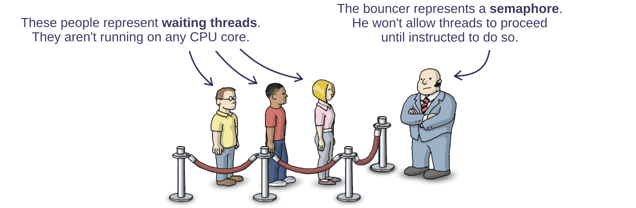
Each thread decides for itself when to join the queue. Dijkstra called this the P operation. P originally stood for some funny-sounding Dutch word, but in a modern semaphore implementation, you’re more likely to see this operation called wait. Basically, when a thread calls the semaphore’s wait operation, it enters the lineup.
The bouncer, himself, only needs to understand a single instruction. Originally, Dijkstra called this the V operation. Nowadays, the operation goes by various names, such as post, release or signal. I prefer signal. Any running thread can call signal at any time, and when it does, the bouncer releases exactly one waiting thread from the queue. (Not necessarily in the same order they arrived.)
Now, what happens if some thread calls signal before there are any threads waiting in line? No problem: As soon as the next thread arrives in the lineup, the bouncer will let it pass directly through. And if signal is called, say, 3 times on an empty lineup, the bouncer will let the next 3 threads to arrive pass directly through.
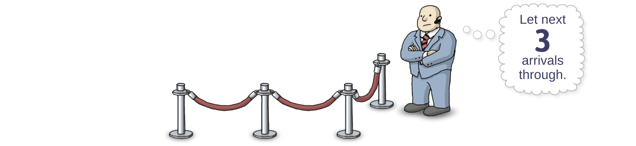
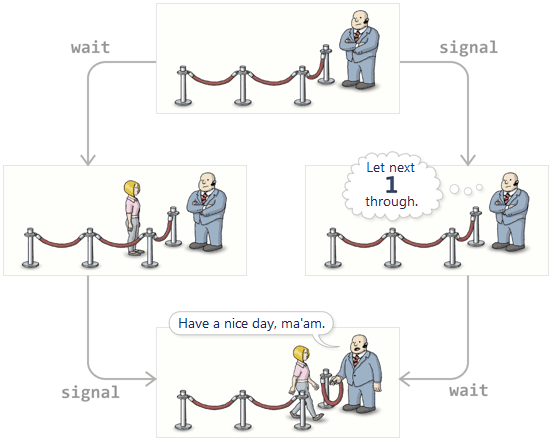
Of course, the bouncer needs to keep track of this number, which is why all semaphores maintain an integer counter. signal increments the counter, and wait decrements it.
The beauty of this strategy is that if wait is called some number of times, and signal is called some number of times, the outcome is always the same: The bouncer will always release the same number of threads, and there will always be the same number of threads left waiting in line, regardless of the order in which those wait and signal calls occurred.
1. A Lightweight Mutex
I’ve already shown how to implement a lightweight mutex in an earlier post. I didn’t know it at the time, but that post was just one example of a reusable pattern. The trick is to build another mechanism in front of the semaphore, which I like to call the box office.
The box office is where the real decisions are made. Should the current thread wait in line? Should it bypass the queue entirely? Should another thread be released from the queue? The box office cannot directly check how many threads are waiting on the semaphore, nor can it check the semaphore’s current signal count. Instead, the box office must somehow keep track of its own previous decisions. In the case of a lightweight mutex, all it needs is an atomic counter. I’ll call this counter m_contention, since it keeps track of how many threads are simultaneously contending for the mutex.
class LightweightMutex { private: std::atomic<int> m_contention; // The "box office" Semaphore m_semaphore; // The "bouncer"
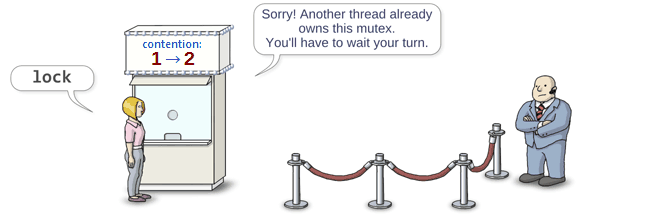
When a thread decides to lock the mutex, it first visits the box office to increment m_contention.
public: void lock() { if (m_contention.fetch_add(1, std::memory_order_acquire) > 0) // Visit the box office { m_semaphore.wait(); // Enter the wait queue } }
If the previous value was 0, that means no other thread has contended for the mutex yet. As such, the current thread immediately considers itself the new owner, bypasses the semaphore, returns from lock and proceeds into whatever code the mutex is intended to protect.
Otherwise, if the previous value was greater than 0, that means another thread is already considered to own the mutex. In that case, the current thread must wait in line for its turn.
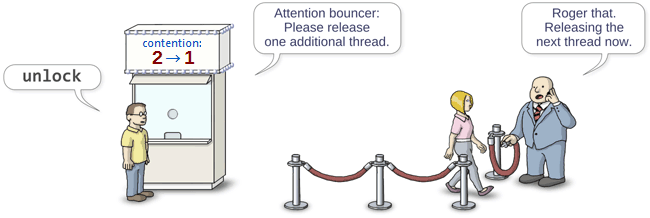
When the previous thread unlocks the mutex, it visits the box office to decrement the counter:
void unlock() { if (m_contention.fetch_sub(1, std::memory_order_release) > 1) // Visit the box office { m_semaphore.signal(); // Release a waiting thread from the queue } }
If the previous counter value was 1, that means no other threads arrived in the meantime, so there’s nothing else to do. m_contention is simply left at 0.
Otherwise, if the previous counter value was greater than 1, another thread has attempted to lock the mutex, and is therefore waiting in the queue. As such, we alert the bouncer that it’s now safe to release the next thread. That thread will be considered the new owner.
Every visit to the box office is an indivisible, atomic operation. Therefore, even if multiple threads call lock and unlock concurrently, they will always visit the box office one at a time. Furthermore, the behavior of the mutex is completely determined by the decisions made at the box office. After they visit the box office, they may operate on the semaphore in an unpredictable order, but that’s OK. As I’ve already explained, the outcome will remain valid regardless of the order in which those semaphore operations occur. (In the worst case, some threads may trade places in line.)
This class is considered “lightweight” because it bypasses the semaphore when there’s no contention, thereby avoiding system calls. I’ve published it to GitHub as NonRecursiveBenaphore along with a recursive version. However, there’s no need to use these classes in practice. Most available mutex implementations are already lightweight. Nonetheless, they’re noteworthy for serving as inspiration for the rest of the primitives described here.
2. A Lightweight Auto-Reset Event Object
You don’t hear autoreset event objects discussed very often, but as I mentioned in my CppCon 2014 talk, they’re widely used in game engines. Most often, they’re used to notify a single other thread (possibly sleeping) of available work.
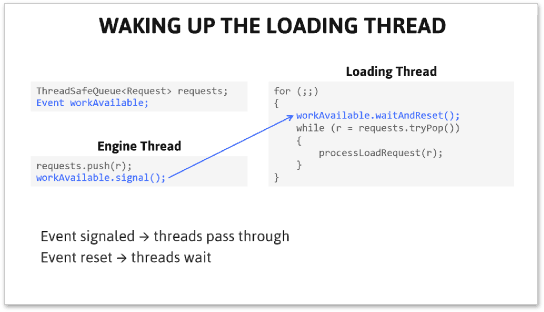
An autoreset event object is basically a semaphore that ignores redundant signals. In other words, when signal is called multiple times, the event object’s signal count will never exceed 1. That means you can go ahead and publish work units somewhere, blindly calling signal after each one. It’s a flexible technique that works even when you publish work units to some data structure other than a queue.
Windows has native support for event objects, but its SetEvent function – the equivalent of signal – can be expensive. One one machine, I timed it at 700 ns per call, even when the event was already signaled. If you’re publishing thousands of work units between threads, the overhead for each SetEvent can quickly add up.
Luckily, the box office/bouncer pattern reduces this overhead significantly. All of the autoreset event logic can be implemented at the box office using atomic operations, and the box office will invoke the semaphore only when it’s absolutely necessary for threads to wait.
I’ve published the implementation as AutoResetEvent. This time, the box office has a different way to keep track of how many threads have been sent to wait in the queue. When m_status is negative, its magnitude indicates how many threads are waiting:
class AutoResetEvent { private: // m_status == 1: Event object is signaled. // m_status == 0: Event object is reset and no threads are waiting. // m_status == -N: Event object is reset and N threads are waiting. std::atomic<int> m_status; Semaphore m_sema;
In the event object’s signal operation, we increment m_status atomically, up to the limit of 1:
public: void signal() { int oldStatus = m_status.load(std::memory_order_relaxed); for (;;) // Increment m_status atomically via CAS loop. { assert(oldStatus <= 1); int newStatus = oldStatus < 1 ? oldStatus + 1 : 1; if (m_status.compare_exchange_weak(oldStatus, newStatus, std::memory_order_release, std::memory_order_relaxed)) break; // The compare-exchange failed, likely because another thread changed m_status. // oldStatus has been updated. Retry the CAS loop. } if (oldStatus < 0) m_sema.signal(); // Release one waiting thread. }
Note that because the initial load from m_status is relaxed, it’s important for the above code to call compare_exchange_weak even if m_status already equals 1. Thanks to commenter Tobias Brüll for pointing that out. See this README file for more information.
3. A Lightweight Read-Write Lock
Using the same box office/bouncer pattern, it’s possible to implement a pretty good read-write lock. This read-write lock is completely lock-free in the absence of writers, it’s starvation-free for both readers and writers, and just like the other primitives, it can spin before putting threads to sleep. It requires two semaphores: one for waiting readers, and another for waiting writers. The code is available as NonRecursiveRWLock.
4. Another Solution to the Dining Philosophers Problem
The box office/bouncer pattern can also solve Dijkstra’s dining philosophers problem in a way that I haven’t seen described elsewhere. If you’re not familiar with this problem, it involves philosophers that share dinner forks with each other. Each philosopher must obtain two specific forks before he or she can eat. I don’t believe this solution will prove useful to anybody, so I won’t go into great detail. I’m just including it as further demonstration of semaphores’ versatility.
In this solution, we assign each philosopher (thread) its own dedicated semaphore. The box office keeps track of which philosophers are eating, which ones have requested to eat, and the order in which those requests arrived. With that information, the box office is able to shepherd all philosophers through their bouncers in an optimal way.
I’ve posted two implementations. One is DiningPhilosophers, which implements the box office using a mutex. The other is LockReducedDiningPhilosophers, in which every visit to the box office is lock-free.
5. A Lightweight Semaphore with Partial Spinning
You read that right: It’s possible to combine a semaphore with a box office to implement… another semaphore.
Why would you do such a thing? Because you end up with a LightweightSemaphore. It becomes extremely cheap when the lineup is empty and the signal count climbs above zero, regardless of how the underlying semaphore is implemented. In such cases, the box office will rely entirely on atomic operations, leaving the underlying semaphore untouched.
Not only that, but you can make threads wait in a spin loop for a short period of time before invoking the underlying semaphore. This trick helps avoid expensive system calls when the wait time ends up being short.
In the GitHub repository, all of the other primitives are implemented on top of LightweightSemaphore, rather than using Semaphore directly. That’s how they all inherit the ability to partially spin. LightweightSemaphore sits on top of Semaphore, which in turn encapsulates a platform-specific semaphore.
The repository comes with a simple test suite, with each test case exercising a different primitive. It’s possible to remove LightweightSemaphore and force all primitives to use Semaphore directly. Here are the resulting timings on my Windows PC:
| LightweightSemaphore | Semaphore | |
|---|---|---|
| testBenaphore | 375 ms | 5503 ms |
| testRecursiveBenaphore | 393 ms | 404 ms |
| testAutoResetEvent | 593 ms | 4665 ms |
| testRWLock | 598 ms | 7126 ms |
| testDiningPhilosophers | 309 ms | 580 ms |
As you can see, the test suite benefits significantly from LightweightSemaphore in this environment. Having said that, I’m pretty sure the current spinning strategy is not optimal for every environment. It simply spins a fixed number of 10000 times before falling back on Semaphore. I looked briefly into adaptive spinning, but the best approach wasn’t obvious. Any suggestions?
Comparison With Condition Variables
With all of these applications, semaphores are more general-purpose than I originally thought – and this wasn’t even a complete list. So why are semaphores absent from the standard C++11 library? For the same reason they’re absent from Boost: a preference for mutexes and condition variables. From the library maintainers’ point of view, conventional semaphore techniques are just too error prone.
When you think about it, though, the box office/bouncer pattern shown here is really just an optimization for condition variables in a specific case – the case where all condition variable operations are performed at the end of the critical section.
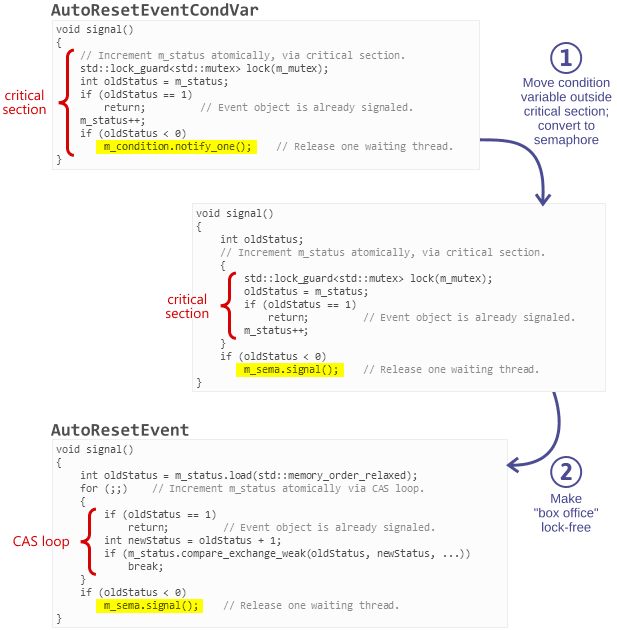
Consider the AutoResetEvent class described above. I’ve implemented AutoResetEventCondVar, an equivalent class based on a condition variable, in the same repository. Its condition variable is always manipulated at the end of the critical section.
void AutoResetEventCondVar::signal() { // Increment m_status atomically via critical section. std::unique_lock<std::mutex> lock(m_mutex); int oldStatus = m_status; if (oldStatus == 1) return; // Event object is already signaled. m_status++; if (oldStatus < 0) m_condition.notify_one(); // Release one waiting thread. }
We can optimize AutoResetEventCondVar in two steps:
-
Pull each condition variable outside of its critical section and convert it to a semaphore. The order-independence of semaphore operations makes this safe. After this step, we’ve already implemented the box office/bouncer pattern. (In general, this step also lets us avoid a thundering herd when multiple threads are signaled at once.)
-
Make the box office lock-free by converting all operations to CAS loops, greatly improving its scalability. This step results in
AutoResetEvent.
On my Windows PC, using AutoResetEvent in place of AutoResetEventCondVar makes the associated test case run 10x faster.